
RAG 知识库重建时,我会先做一条可回滚的影子索引

最近给一个内部 RAG 知识库补全量重建能力时,我又踩到一个熟悉的问题:文档源变化很快,线上检索还在跑,重建任务一旦直接覆盖原集合,就很容易出现新旧 chunk 混在一起、embedding 模型版本不一致、回滚缺少依据这些情况。用户看到的结果通常很隐蔽,答案并不会立刻报错,只是引用来源变旧、命中段落变散,排查时成本很高。
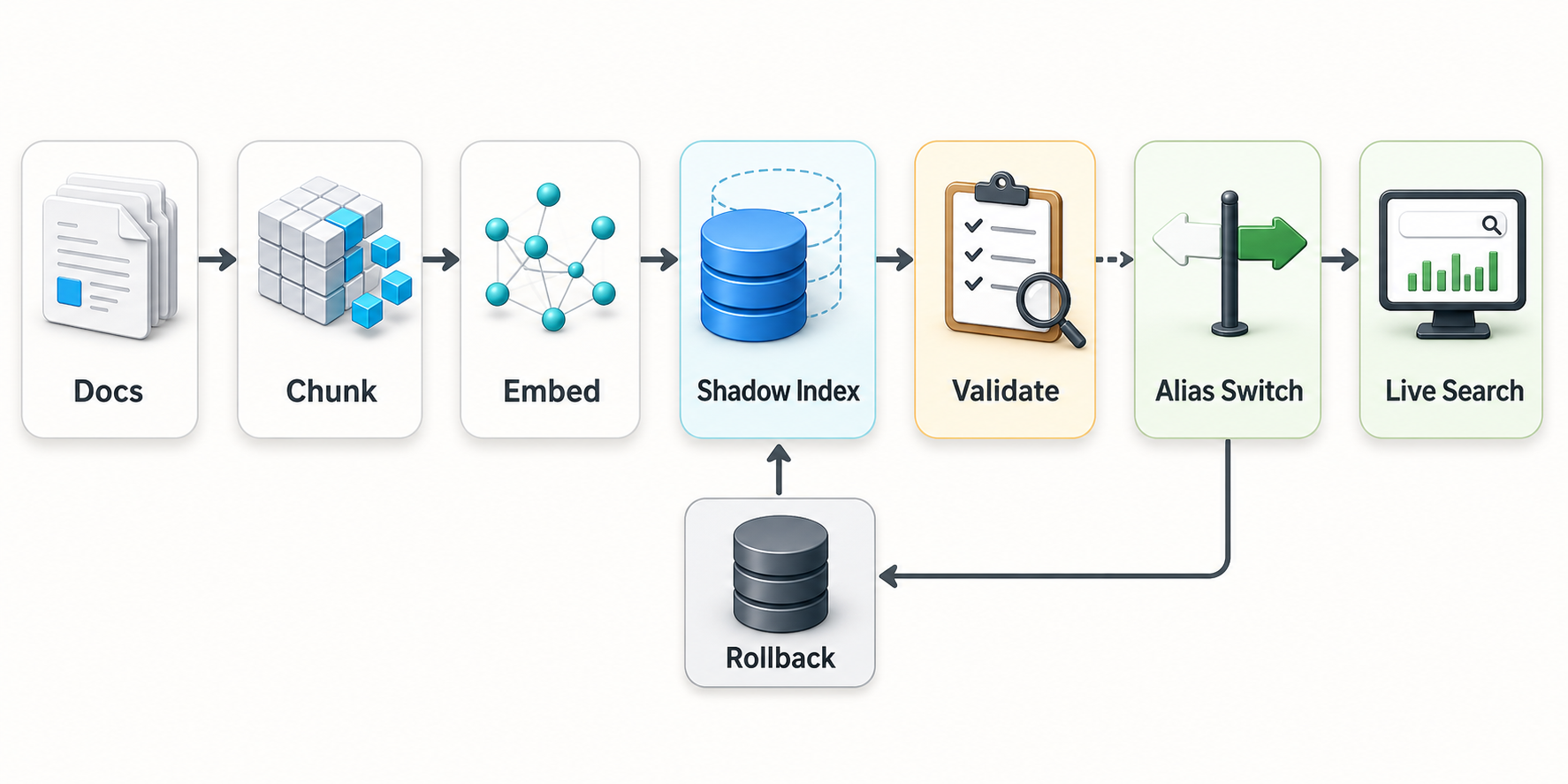
从文档切分、向量写入、影子索引校验到别名切换和回滚的流程示意图 来源:Codex image generation
问题背景
这个知识库的数据来自产品文档、客服 FAQ 和几份内部排障手册。早期实现只关注“能导入”,流程是读取文件、切分文本、生成向量、写入集合,然后刷新检索服务的缓存。文档少的时候,这套流程还能接受。后来文档进入定时同步,导入任务和线上检索会同时发生,重建就变成了一个带状态迁移的发布问题。
LlamaIndex 的 IngestionPipeline 文档把导入拆成 transformations、cache、docstore 和 vector_store 等环节,这个拆法提醒我,RAG 导入不能只看最终集合数量。每一步都应该有输入、输出和可复查的边界,特别是切分策略、元数据规范和向量写入批次。只要这些边界缺少记录,后续的召回异常就很难定位到具体阶段。
最容易被忽略的难点
第一个难点是 chunk 版本。标题提取、分隔符、重叠长度只要改一点,同一份文档就会产生不同的节点。第二个难点是索引可见性。写入中的集合如果被线上查询命中,用户可能拿到半成品结果。第三个难点是回滚。很多团队会保留旧数据文件,却没有保留旧索引入口,真的出问题时只能重新构建,时间窗口会被拉长。
我后来把重建任务改成“影子索引”流程。生产查询始终访问一个稳定别名,例如 kb_current。重建时新建 kb_20260523_1800 这样的集合,后台完成 chunk、embedding、payload 校验和抽样检索。只有校验通过后,才把别名切到新集合。Qdrant 的集合文档里提到,别名可以作为集合的额外名称使用,并且多个别名动作会原子执行,这个能力很适合做向量集合版本切换。
解决思路
我会先把导入任务拆成三张表或三类日志:一次 rebuild run 的状态、一份文档的 hash 与 chunk 数、一批向量写入的成功数量。每次运行都有 run_id,所有文档节点都带上 source_id、source_hash、chunk_version、embedding_model 和 run_id。这样检索结果出现偏差时,可以直接看命中的节点来自哪次重建。
校验阶段不要只看集合里有多少条向量。我会准备一组固定问题,覆盖产品名、错误码、流程步骤和长尾术语,分别查旧集合和影子集合,比较 topK 命中来源、段落长度和重复率。差异太大时先停在影子集合,不切线上入口。这个校验可以很简单,哪怕先用 JSON 文件保存样例问题,也比完全凭感觉发布可靠。
关键步骤
实际落地时,我把流程收敛为五步。第一步生成重建计划,冻结本次文档清单和切分配置。第二步写入影子集合,任何失败都只影响本次 run。第三步跑结构校验,检查 payload 字段、空文本、重复 chunk 和向量数量。第四步跑检索抽样,把结果写进报告。第五步切换别名,并保留旧集合一段时间。线上出问题时,只需要把别名切回旧集合,再分析新集合的数据。
TypeScript 服务里我会把“当前别名”和“物理集合名”分开建模。业务层只知道 kb_current,运维任务才知道具体版本号。这样前端调试台、Electron 桌面端和 Web 管理端都能显示当前指向的索引版本,又不会把物理集合名散落到业务代码里。
可复用经验
RAG 知识库重建和普通数据导入最大的差别在于,检索质量不会用一个异常堆栈提醒你。影子索引的价值是给发布留出观察窗口,也给回滚留出入口。我的经验是,先把 run_id、chunk_version、embedding_model 这些元数据补齐,再谈更复杂的评测框架。等基础记录稳定后,自动化校验、人工抽查和线上监控才能连成一条可持续的工作流。