
Electron 回归失败后,我会把 Trace 和主进程日志一起留成证据包

最近给一个 Electron 工具补自动化回归时,我又遇到一个很典型的桌面端问题:CI 上偶发失败,本地手动点一遍却无法复现。测试报告里只有一张失败截图和一段断言错误,能看到按钮没出现,却看不到它为什么没出现。是渲染进程接口慢了,主进程 IPC 没回,缓存目录权限异常,还是窗口加载时机提前了,截图都回答不了。
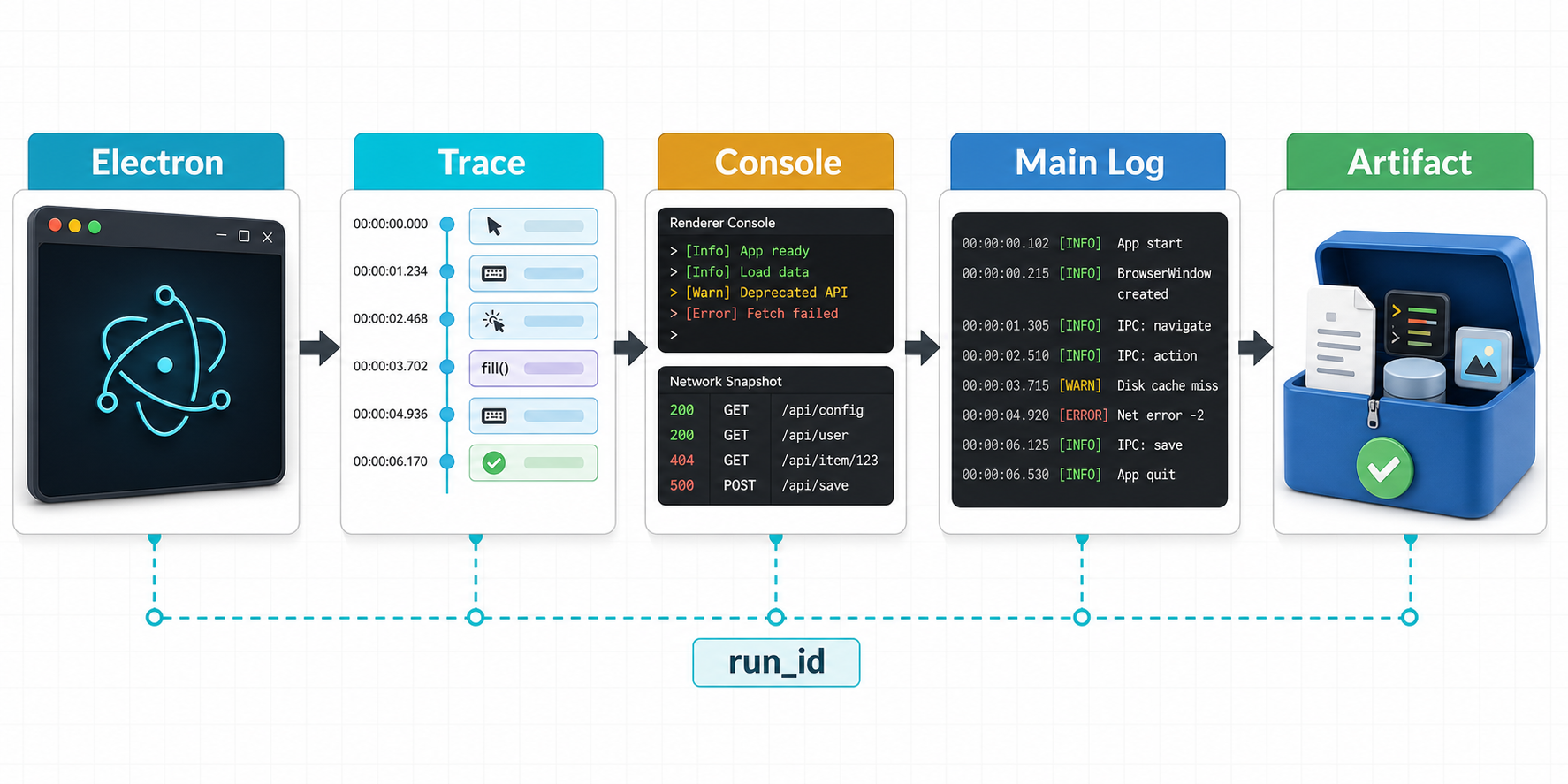
用 run_id 串联 Electron 窗口、Playwright Trace、渲染进程 console、主进程日志和 CI artifact 的调试证据链。 来源:Codex image generation
问题背景
这个工具本身很像一个小型工作台:左侧是任务列表,中间是日志和预览,右侧会把 Agent 运行结果保存成本地文件。前端页面可以用浏览器调试,但真正出问题时,常常牵扯 Electron 主进程、preload、IPC、文件系统和远端 API。Playwright 官方文档里 Electron automation 仍标注为 experimental,并提供了 _electron.launch、firstWindow()、窗口 console 监听、tracesDir 和 artifactsDir 这类能力。我的理解是,它适合做关键流程回归和失败证据收集,使用时要把可观测性补齐。
最麻烦的难点
第一个难点是证据分散。Playwright Trace Viewer 能回放测试动作,查看每一步前后的页面状态,也能看 console、network、source 和错误信息。但 Electron 的主进程日志天然在另一条通道里,窗口里的 Trace 看不到 BrowserWindow 创建、IPC handler、文件写入路径和应用退出时机。
第二个难点是重试会改变现场。Playwright 支持 retries,失败后会换新的 worker 继续跑。这个机制能隔离污染,但也意味着第一次失败和重试成功之间可能丢掉关键线索。如果只在最终失败时保存日志,很多 flaky 问题会变成一句“偶现”。
第三个难点是 AI 辅助排查也需要上下文。把一段错误日志直接丢给模型,往往只能得到泛泛建议。真正有用的输入应该是一次运行的完整故事:测试名、run_id、Trace、渲染进程 console、网络请求、主进程日志、环境变量摘要和产物路径。
解决思路
我后来把回归脚本改成证据优先的流程。每次测试启动时生成一个 run_id,同时写进 Electron 启动参数、渲染进程 localStorage、主进程日志前缀和 Playwright 的输出目录。这样 Trace 里的动作、Console 面板里的错误、主进程 log 文件和 CI artifact 都能用同一个 id 关联。
Trace 仍然交给 Playwright 负责,配置上保留 trace: 'on-first-retry',本地排查时再临时打开 --trace on。主进程日志单独落到 testInfo.outputPath('main.log')。测试结束后用 testInfo.attach() 把 main.log、精简后的环境信息和必要的 JSON 快照挂到报告里。Playwright 文档说明 testInfo.attach() 会把附件复制到 reporter 可访问的位置,这正好适合 CI 留档。
Electron 主进程调试我会留一个人工入口。官方文档建议用 --inspect 或 --inspect-brk 配合外部调试器调试主进程,所以脚本里保留 E2E_MAIN_INSPECT=1 开关。自动化跑 CI 时不开,定位疑难问题时再让主进程停在第一行,接 Chrome 或 VS Code 看启动阶段。
关键步骤
我的落地步骤很固定。先写一个 launchElectronForTest(),集中处理 _electron.launch 参数、临时用户目录、run_id 和日志路径。再给窗口挂上 window.on('console'),把 renderer 的错误按时间写入同一个输出目录。接着在关键业务动作外包一层 test.step(),让 Trace 的时间线能看出“打开任务”“触发运行”“等待结果”“保存文件”这些业务节点。
失败时,我不会只保留最后一张截图。脚本会收集四类东西:Trace zip、主进程日志、renderer console 摘要、关键状态 JSON。需要给 AI 分析时,先把这四类证据整理成一段短上下文,再附上失败断言和最近一次相关代码变更。这样模型更容易判断问题发生在 UI 等待、IPC 返回、接口状态,还是本地文件写入。
可复用经验
Electron 自动化测试的价值不只在于“点得动”,更在于失败后能不能复盘。桌面端比纯 Web 多了主进程和系统资源边界,证据如果只停留在截图层,很容易把排查推回人工猜测。我的经验是,先统一 run_id,再把 Trace、console、network、main log 和 artifact 绑定到一次运行。等这条链路稳定后,AI 工具才有足够上下文参与排查,CI 报告也能从“失败了”变成“这次失败留下了可分析材料”。