
Agent 工具一重试就重复扣资源,我后来把 run_id、幂等键和补偿日志绑在了一起
最近在整理一个带 Agent 工作流的内部工具时,我踩到一个很典型的坑:模型侧其实只发起了一次工具调用,调度层却因为超时重试、页面刷新和队列回放,把同一个副作用执行了两到三次。最明显的现象是同一份文档被重复入库、同一条外部 API 被重复扣额度、任务面板里还出现了互相打架的状态。
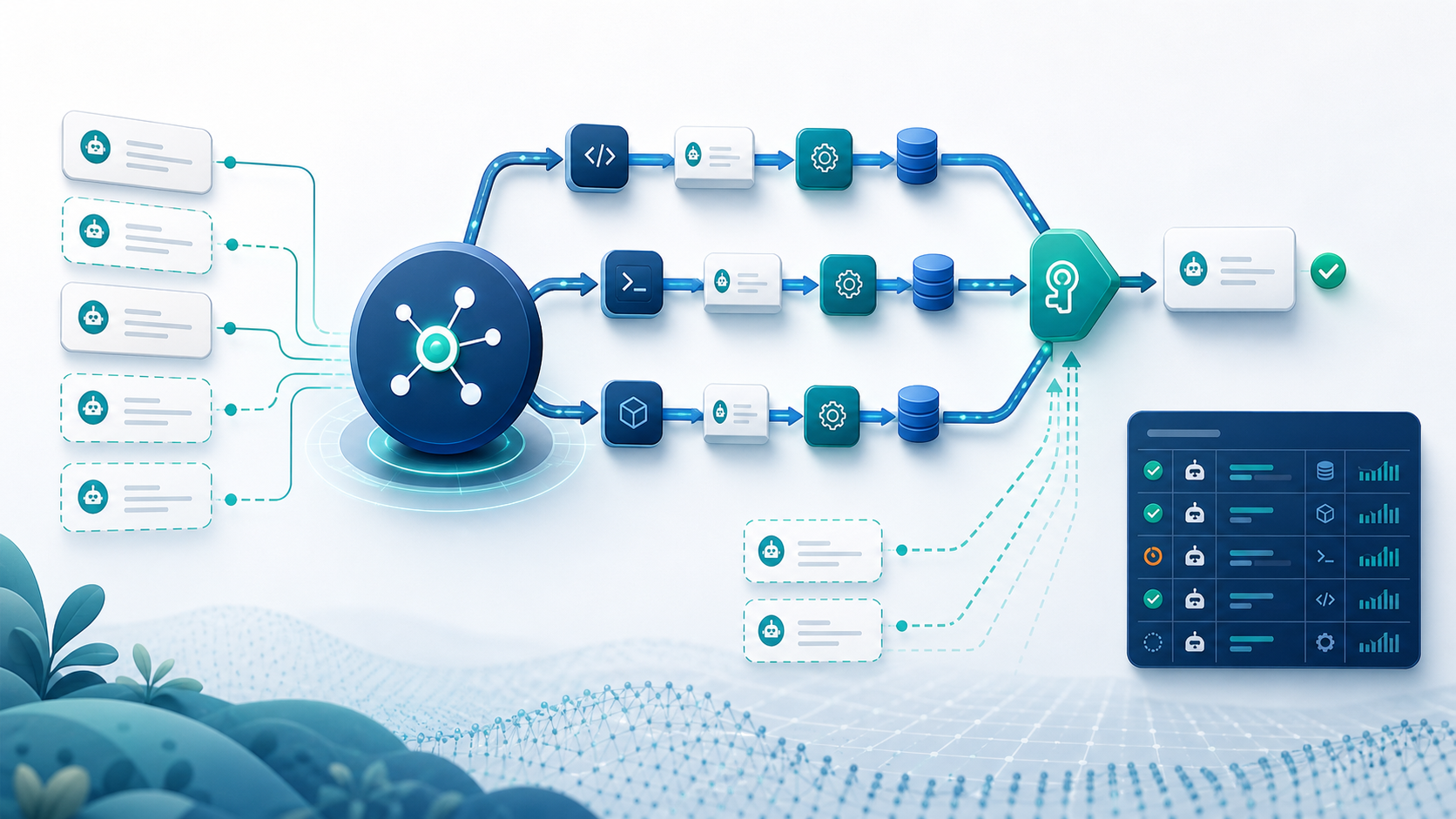
原创示意图:调度器先分配执行标识,再由幂等门禁约束重复副作用,并把恢复动作写入补偿日志。 来源:Codex image generation
问题背景
OpenAI 的 function calling 文档把工具调用定义成应用和模型之间的多步交互,模型给出调用意图,真正执行代码的是我们自己的应用层。这一层一旦接了队列、数据库和外部服务,重试就很难完全避免。问题在于,大多数 AI Demo 都把重点放在“工具能不能调起来”,工程化以后真正难的是“调失败、调慢、调到一半时,系统还能不能稳住”。
我这次碰到的故障链路很真实。用户在桌面端点了一次“重新索引知识库”,Agent 先拆出扫描目录、生成切片、写入向量库、刷新摘要四个步骤。扫描阶段超时后,队列开始重试;用户看到界面没动静,又手动点了一次;后台恢复任务时又把未完成步骤捞了一遍。最后系统没有崩,但外部副作用全都重复了,排查成本比接口 500 还高。
我踩到的几个坑
第一个坑是只给“任务”加状态,没有给“执行”加稳定主键。任务看起来只有一条,真正落到工具层时已经变成多次执行。第二个坑是把幂等判断放在内存里,进程重启以后就全丢了。第三个坑是副作用执行成功了,状态写回失败,后续重试又会把成功动作再做一遍。第四个坑是日志只有报错信息,没有记录补偿动作,导致我知道哪里重复了,却看不清系统后来怎么把现场拉回来的。
解决思路
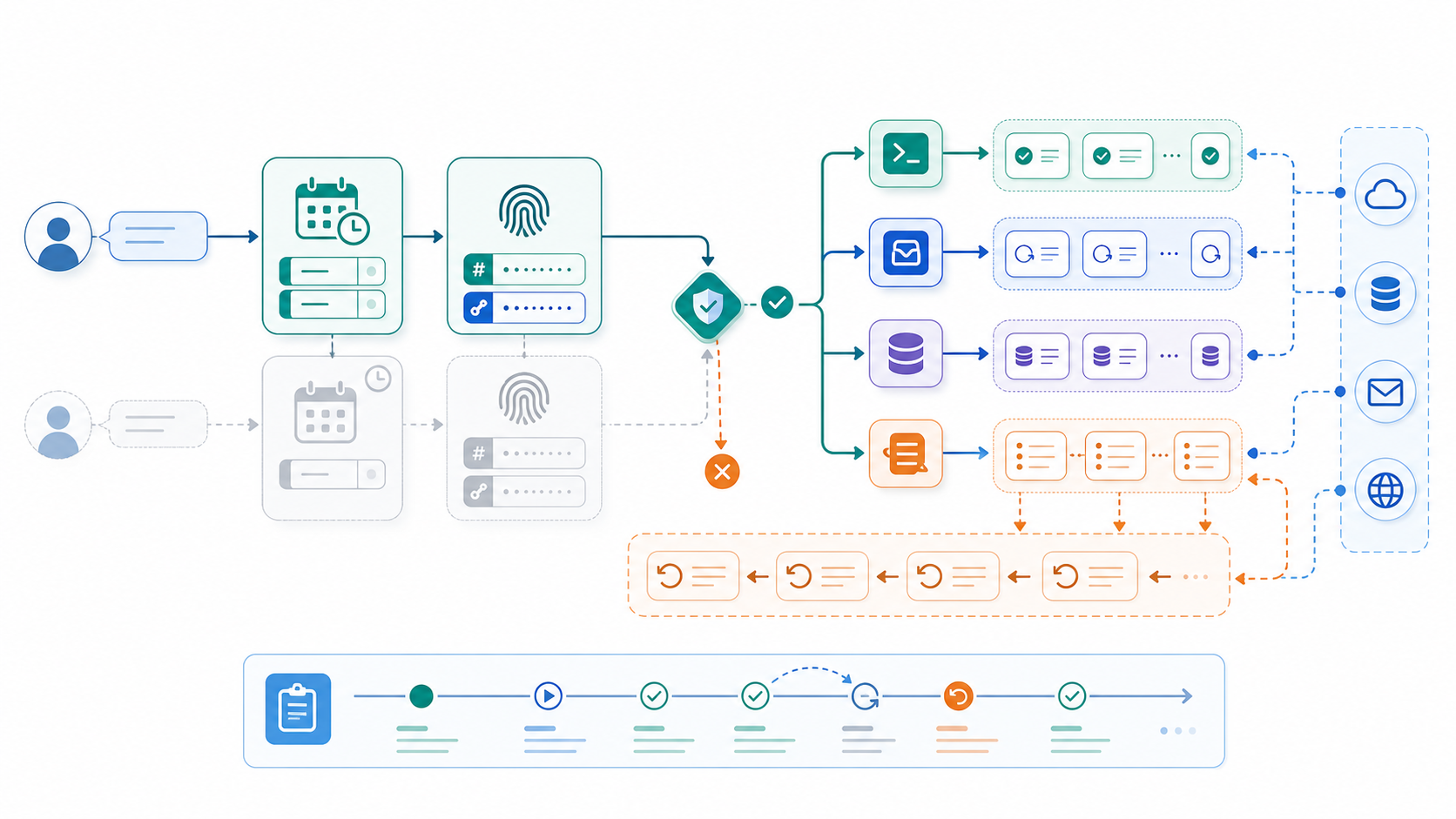
后面我把整条链路改成三层键值。task_id 表示业务任务,run_id 表示一次调度执行,idempotency_key 表示某个外部副作用的唯一主键。task_id 解决的是面板可追踪,run_id 解决的是多次重试可区分,idempotency_key 解决的是外部调用只能生效一次。只要步骤会写数据库、发 HTTP、扣配额、创建文件,我都会在真正执行前先查这把键。
这个思路有两个外部参考对我帮助很大。Stripe 官方把 idempotent requests 讲得非常直接,安全重试的前提是由调用方提供稳定键,并让服务端记住第一次结果。Temporal 文档里对 durable execution 的描述也很有启发,系统要把“中断后从哪里继续”当成默认前提来设计。放到 Agent 工作流里,含义就是调度层不能只关心模型输出,还要把每一步副作用的去重和恢复都建模出来。
关键步骤
1. 请求进入编排层时先生成 run_id,并把它透传到队列、工具执行器和前端面板。 2. 每个会产生副作用的步骤都派生一个稳定的 idempotency_key,组成可以是 task_id + step_name + input_hash。 3. 工具执行前先查持久化存储,如果这把键已经成功执行,直接复用结果,不再重复调用外部系统。 4. 工具执行成功后,先写执行结果和副作用摘要,再更新任务状态,避免“动作成功但状态丢失”触发二次重试。 5. 对不能天然回滚的步骤单独记补偿日志,比如删除临时文件、撤销草稿、标记过期向量分片,后续统一由恢复任务处理。
可复用经验
这次改完以后,我对 Agent 工程化有了一个更稳的判断:只要工作流里出现了工具调用、队列重试和外部副作用,幂等设计就该在第一版里出现。把 run_id、幂等键和补偿日志提前立住,后面接 RAG、桌面端任务面板、自动发布脚本都会轻很多。模型输出本身会波动,副作用链路必须尽量稳定,这样系统才经得住长时间运行。