
Electron 和 Web 共用一套 TypeScript 合同时,我怎样把 IPC、HTTP 和后台任务都收口到 Zod

最近在整理一个同时有 Electron 桌面端、Web 控制台和后台任务队列的 AI 工具时,我发现最耗时间的故障并不在模型调用本身,而是在数据边界。渲染层点一个按钮,可能先走 preload 暴露的方法,再转成 IPC 请求进入主进程;同一份任务结果有时又会通过 HTTP 回到 Web 端,最后落到本地缓存里。只要其中一层字段名漂移、可选项理解不一致,问题就会变成“编译能过,运行才炸”,排查成本非常高。
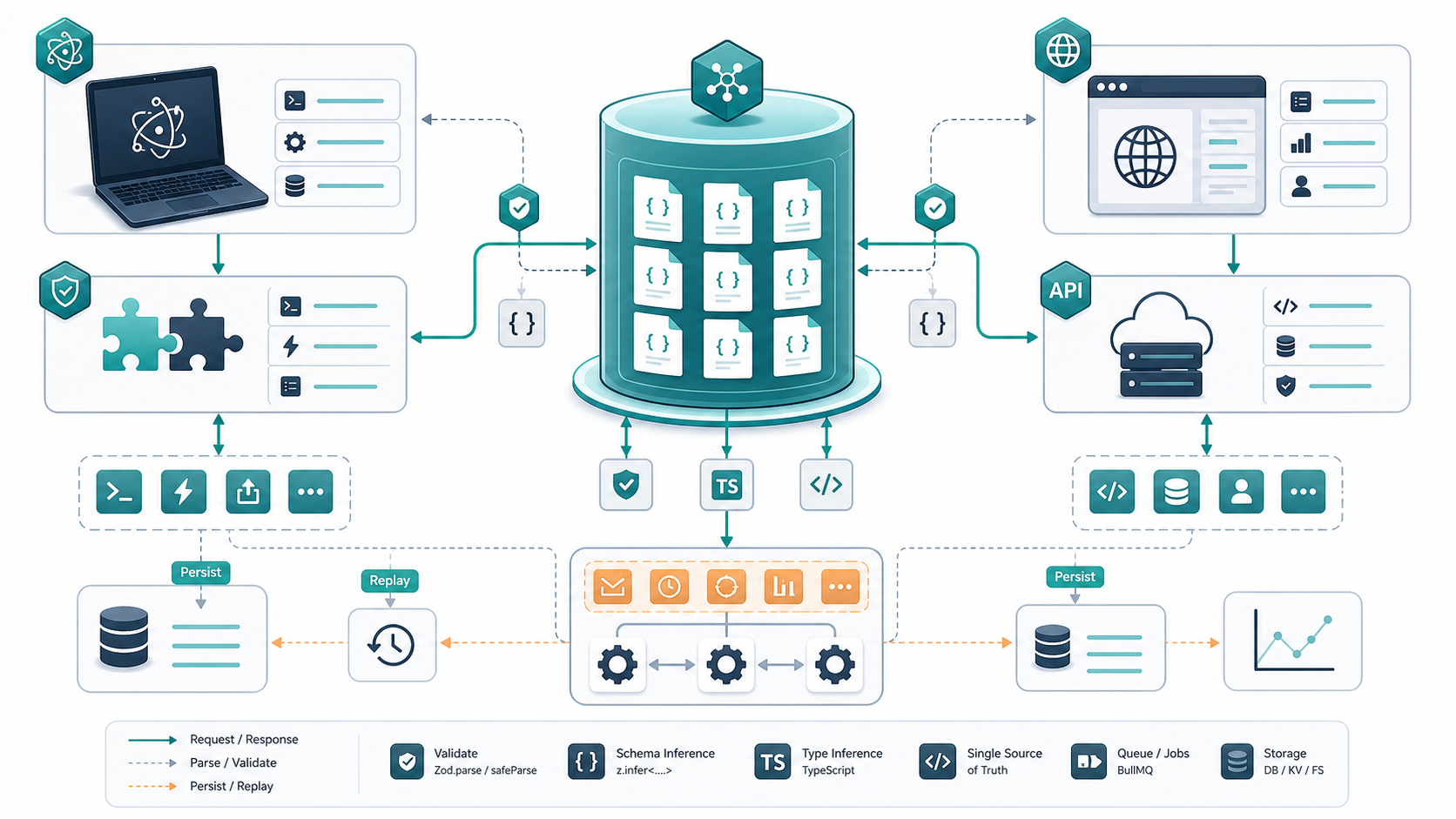
原创示意图:以共享 schema 为中心,把 Electron preload、IPC、HTTP API 和后台任务队列收口到同一份运行时合同。 来源:Codex image generation
问题背景
最早那版实现里,桌面端的 IPC payload、服务端 DTO、前端表单状态和任务回放记录各自维护类型。TypeScript 在单个项目里当然能给提示,但提示的前提是这份类型真的被大家共用。实际开发时,最容易发生的是 renderer 手写一份接口,main 进程又补一份,服务端再抄一份,字段看起来差不多,细节却慢慢偏掉。Electron 官方文档对 context isolation 和 IPC 的边界写得很明确,preload 应该暴露窄接口,每个 IPC 动作都要有明确通道;这意味着只要桥接层一多,手写类型副本也会跟着增殖。
我踩过的几个坑
第一个坑是“类型对了,数据却不对”。比如前端把 updatedAt 当字符串,主进程当 Date,任务快照写进本地时又序列化成时间戳,最后 UI 里同一个字段要写三套转换。第二个坑是错误位置漂移。接口字段漏传以后,HTTP 场景还能在服务端拿到比较清晰的 400,IPC 场景却经常变成主进程内部异常,堆栈离真实原因很远。第三个坑是长期演进时的局部修补。某次为了兼容旧任务记录,我在 renderer 里临时兜底,过几周又在主进程补了一层默认值,最后没人说得清真正的合同长什么样。
收口方案
后面我把思路改成共享 schema 先行。所有跨边界的数据结构都先在一个 contracts 包里定义成 Zod schema,然后再从 schema 推导 TypeScript 类型。这样 renderer 发 IPC 前先校验一次,main 进程收到后再校验一次,服务端入参和后台任务出参继续沿用同一份定义。Zod 文档把 .parse、.safeParse 和 z.infer 这套组合讲得很清楚,拿它做边界校验很顺手。对 Electron 这类多进程应用尤其有用,因为 contextBridge 暴露出去的每个方法都能绑定一份明确的输入输出合同,桥接层不再只是“转发消息”,而是顺手把错误挡在入口。
关键步骤
1. 先只抽跨边界对象,不急着抽内部领域模型,优先处理 IPC 请求、HTTP 响应、任务快照这三类最容易漂移的数据。 2. preload 层只暴露动作级方法,例如 startTask、loadTask、cancelTask,每个方法在调用 ipcRenderer.invoke 前先做一次 schema 校验。 3. 主进程收到消息后继续校验,同一份 schema 失败时统一返回结构化错误,别把内部异常直接抛给 UI。 4. Web 端请求服务端时沿用同一个 contracts 包,避免表单类型、接口类型和任务结果类型分叉。 5. 对需要兼容旧数据的场景,把兼容逻辑写进 schema 附近集中管理,别把兜底代码散落在 renderer、main 和 server 三处。
可复用经验
这次改完以后,我对桌面端和 Web 端协作有了一个更稳定的判断:只要数据要跨进程、跨网络或者跨持久化边界流动,就值得先把共享合同立住。TypeScript 负责在编辑期约束开发体验,Zod 负责在运行时拦住脏数据,两层一起用,排障速度会快很多。后面不管再接 Agent 工作流、RAG 检索结果还是自动化任务面板,我都会先问自己一句,真正应该被复用的到底是组件,还是这份跨边界合同。