
给 RAG 导入大文件前,我会先把上传队列做成可恢复状态机

最近给一个 RAG 知识库管理端补大文件导入时,我发现最容易被低估的环节其实在切分之前。用户拖进来的 PDF、Markdown 压缩包和导出日志还没有进入 embedding 流程,浏览器端就已经要处理断网、刷新、重复提交、超时和文件校验。上传链路不稳,后面的清洗、分块、入库和检索评测都会变成脏数据排查。
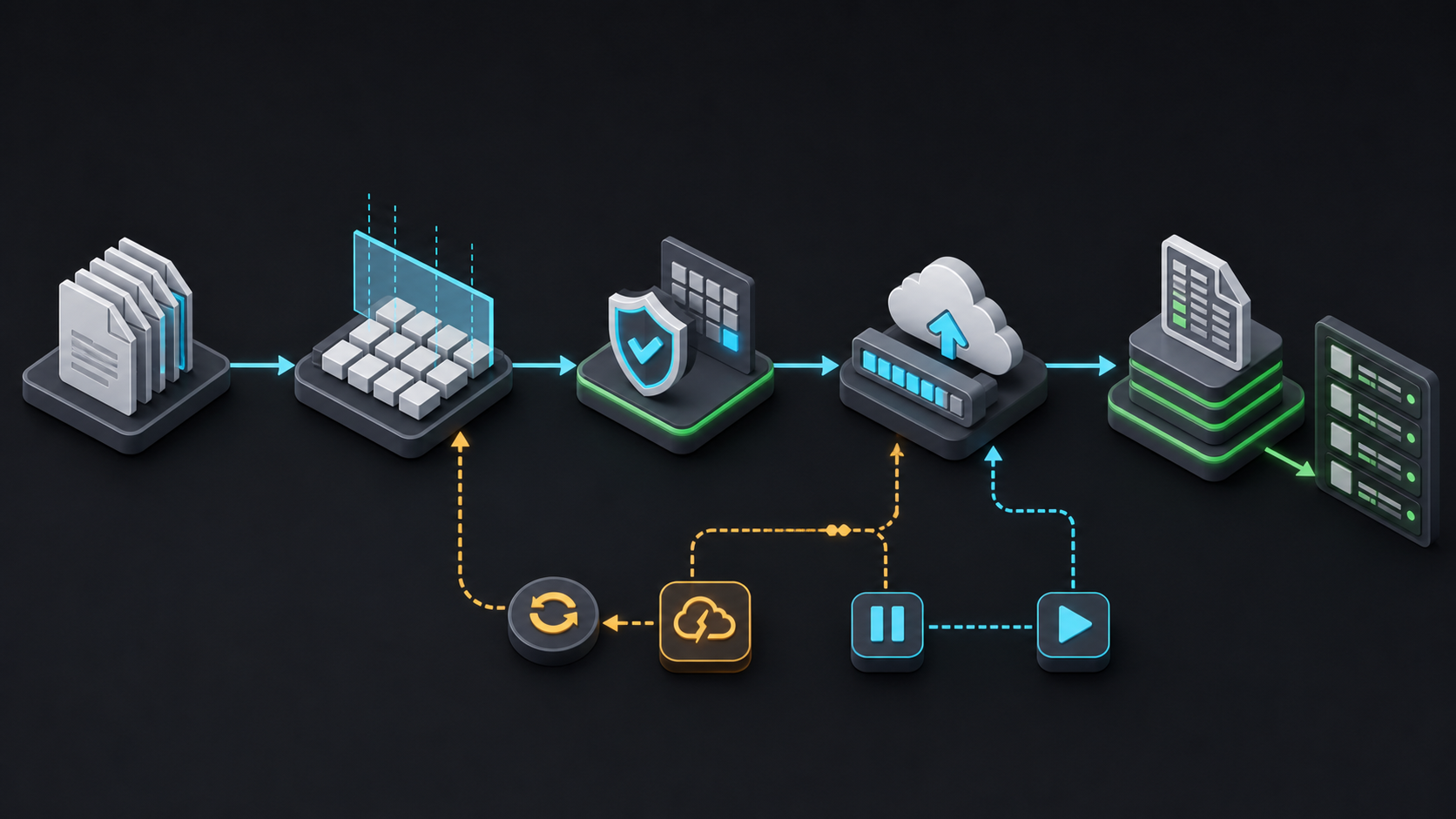
从文件选择、分块、校验、暂停恢复到入库的队列状态流。 来源:Codex image generation
问题背景
这个管理端经常一次导入几十到几百个文件,前端先收集文件元信息,再交给后端解析和向量化。MDN 的 File API 文档说明,用户通过文件选择或拖拽授权后,Web 应用可以访问文件内容,并读取名称、大小、类型和修改时间。这些信息正好适合作为导入任务的第一层身份。
早期实现里,刷新丢任务、同名文件重复入队、取消后后台仍在解析,是最常见的三个故障。上传阶段没有清楚边界,后面的索引异常就很难复盘。
关键难点
第一个难点是文件身份不能只靠文件名。我会把 name、size、lastModified 和一次内容摘要组合成 fileKey,让 UI 队列、上传接口和后端导入记录使用同一个身份。这里要注意 MDN 对 SubtleCrypto.digest() 的说明,它会生成输入数据的摘要,但不支持流式输入,需要把输入整体读入内存。因此前端只适合做小文件摘要或分块摘要,大文件最终校验仍应交给后端完成。
第二个难点是恢复点要对齐字节偏移。tus 官方协议把可恢复上传建立在 HTTP 之上,核心流程会用 HEAD 查询当前 Upload-Offset,再用 PATCH 从该偏移继续传输。这个模型给了我一个清楚边界:前端保存本地文件身份、远端上传地址、已确认偏移和当前状态,后端确认实际接收了多少字节。
第三个难点是 UI 状态边界。上传、暂停、重试、取消、校验失败、等待入库,如果散落在组件里,后面做自动化导入和错误复盘会很痛苦。
解决思路
我后来把导入前置为一台小状态机。每个文件从 queued 开始,经过 hashing、uploading、verifying、ingesting,最终进入 done 或 failed。暂停和重试是状态迁移,取消是明确的终止动作。前端只展示状态机快照,不直接猜后端进度。
文件读取也收口到队列服务里。MDN 的 ReadableStream 文档把它描述为可读的字节数据流,这提醒我让组件只负责添加文件、展示进度和发出用户意图;队列服务负责限流、偏移确认、重试退避和持久化快照。
关键步骤
落地时我先建立本地队列表,字段保持简单:fileKey、文件元信息、上传会话地址、已确认偏移、状态、错误码和创建时间。刷新页面时先恢复快照,再对未完成任务执行一次远端偏移查询。
重试条件也要写清楚。网络超时可以重试,偏移冲突要先重新 HEAD,文件内容变化要直接失败,用户取消要停止后续解析。这样日志里看到失败原因时,可以判断是传输问题、身份问题还是业务校验问题。
最后把上传完成和知识库可检索分成两件事。上传完成只代表文件字节进入后端,后面还要解析、切分、去重、写入向量库和抽样检索。UI 上我会让导入任务继续停在 ingesting,直到后端返回索引版本和来源数量。
可复用经验
RAG 导入的稳定性,经常取决于入库之前的工程细节。我的默认做法是先把上传队列做成可恢复状态机,再接解析和向量化流水线。只要文件身份、远端偏移、状态迁移和错误码稳定,后续接 Electron 桌面端、本地文件夹同步或自动化批量导入时,都能复用同一套边界。
每次导入我还会生成轻量报告,记录已上传、已解析、已写入索引和校验失败的数量。只要能把问题定位到上传、解析或入库阶段,就能节省很多排障时间。