
给小服务加观测前,我会先用 OpenTelemetry Collector 收拢三类信号

导语:小服务刚开始接可观测性时,最容易把问题做散。应用里加一个导出器,日志系统再配一个采集器,指标又连到另一个后端,等到排查慢请求时,Trace、日志和资源信息很难对齐。我现在更倾向于先在本地放一层 OpenTelemetry Collector,把三类信号收进同一条可检查的管道,跑通后再决定接哪一个云端或自托管后端。
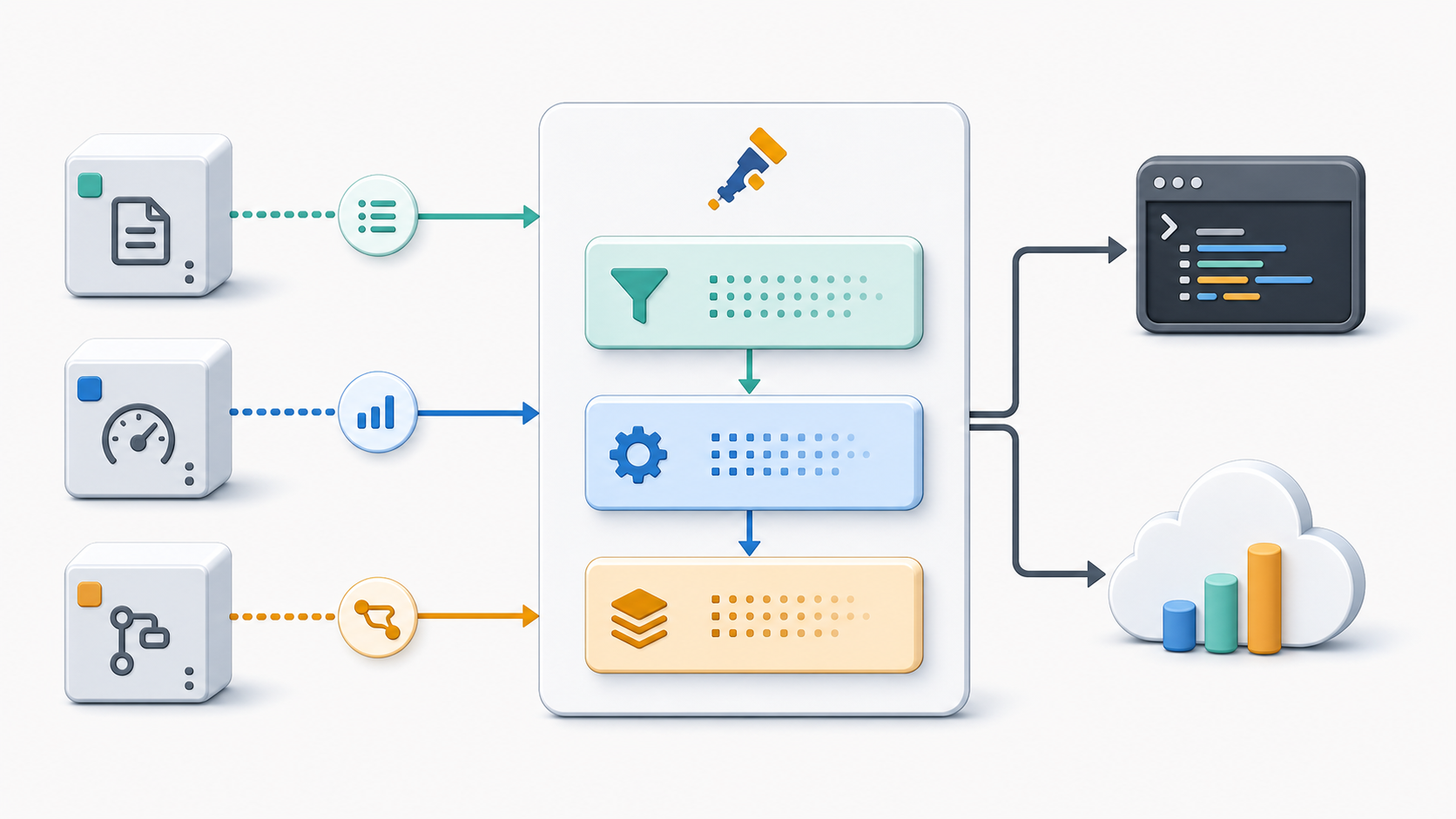
从服务信号进入 Collector,再经过处理阶段导出到本地或云端后端的流程示意图 来源:Codex image generation
先把出口放到 Collector
OpenTelemetry 官方文档把 Collector 定位为与厂商无关的遥测接收、处理和导出实现。它能接收应用发来的数据,经过处理后再导出到一个或多个后端。对小团队来说,这个抽象很实用:应用代码只需要稳定地把 OTLP 发到本地 Collector,后面的批处理、重试、脱敏、采样、加密和后端切换都可以放在 Collector 配置里逐步调整。
OpenTelemetry 的信号模型也很适合做启动清单。官方概念文档把 Traces、Metrics、Logs、Baggage 列为当前支持的信号,其中 Trace 负责描述请求路径,Metric 记录运行时测量值,Log 记录事件。小服务第一版不用追求全量平台化,先让这三类信号能同时进入 Collector,再用同一个 service.name、环境名和版本号串起来,就能明显降低排障时的上下文切换成本。
配置要按管道思考
Collector 配置的关键在于四类组件:receivers、processors、exporters、connectors。官方配置文档强调,组件写进配置文件后还需要在 service 段的 pipelines 中启用。这个细节很重要,因为它逼着我们把数据流写清楚:谁负责接收,哪些处理器按什么顺序执行,最后导向哪里。
我会从一个最小组合开始。receiver 只开 OTLP 的 gRPC 和 HTTP 入口;processor 先放 memory_limiter 和 batch,避免本地压测时内存不受控,也让导出更稳定;exporter 第一版用 debug 或 file,确认信号结构符合预期后,再换成正式后端的 OTLP、Prometheus 或其他 exporter。这样做的好处是验证路径很短,应用发出的数据能直接在本地看到,后端账号、网络策略和账单因素可以放到第二步处理。
本地验收看三件事
第一件事是端点边界。官方示例里为了演示会出现 0.0.0.0,但文档也提示本地客户端优先绑定 localhost。开发环境如果只给本机服务使用,我会把接收端点限制在本地地址,并把后端 token、证书和导出地址放进环境变量或私有配置。
第二件事是处理顺序。脱敏、丢弃、重命名、采样和批处理都属于 processor 范畴,顺序会影响结果。比如先删除敏感字段再导出 debug,日志里就不会留下调试期的脏数据;先做内存限制和批处理,再接云端 exporter,就能更接近生产链路。
第三件事是可替换出口。Collector 的价值在于出口可以变,应用侧契约保持稳定。今天可以先导出到本地文件,明天换成云服务,后天再加一个自托管后端。只要 pipeline 命名、资源字段和采样策略有记录,后续迁移就不会牵动每个业务服务。
落地建议
我会把 Collector 当成小服务观测的第一道关口:新增服务时先给它一个 service.name,本地跑通 OTLP 到 Collector,再把日志、指标和 Trace 用同一套资源属性串起来。上线前保留一份最小配置、一次样例输出和一张信号流向图,后面排查慢请求、错误率抖动或资源异常时,团队就有共同语言。
如果项目还没准备接大型观测平台,也可以先用 Collector 做本地演练。它不会替代后端分析能力,但能提前统一数据入口和处理规则。等到真正接入云端或自建后端时,团队调整的是 Collector 配置和密钥管理,应用侧只需要继续稳定发送标准信号。