
把 Postgres 放进浏览器前,我会先用 PGlite 跑一版本地优先原型

如果一个前端原型一开始就接远端数据库,很多问题会被网络、账号、环境变量和测试数据放大。PGlite 的价值在于把 Postgres 作为一个 TypeScript 客户端带进浏览器、Node、Bun 或 Deno,让团队先在本地验证表结构、SQL 查询和离线交互,再决定服务端同步方式。它由 ElectricSQL 维护,GitHub README 说明它是 Postgres 的 WASM 构建,封装成 TypeScript 客户端,压缩后约 3MB,并采用 Apache 2.0 与 PostgreSQL License 双许可。
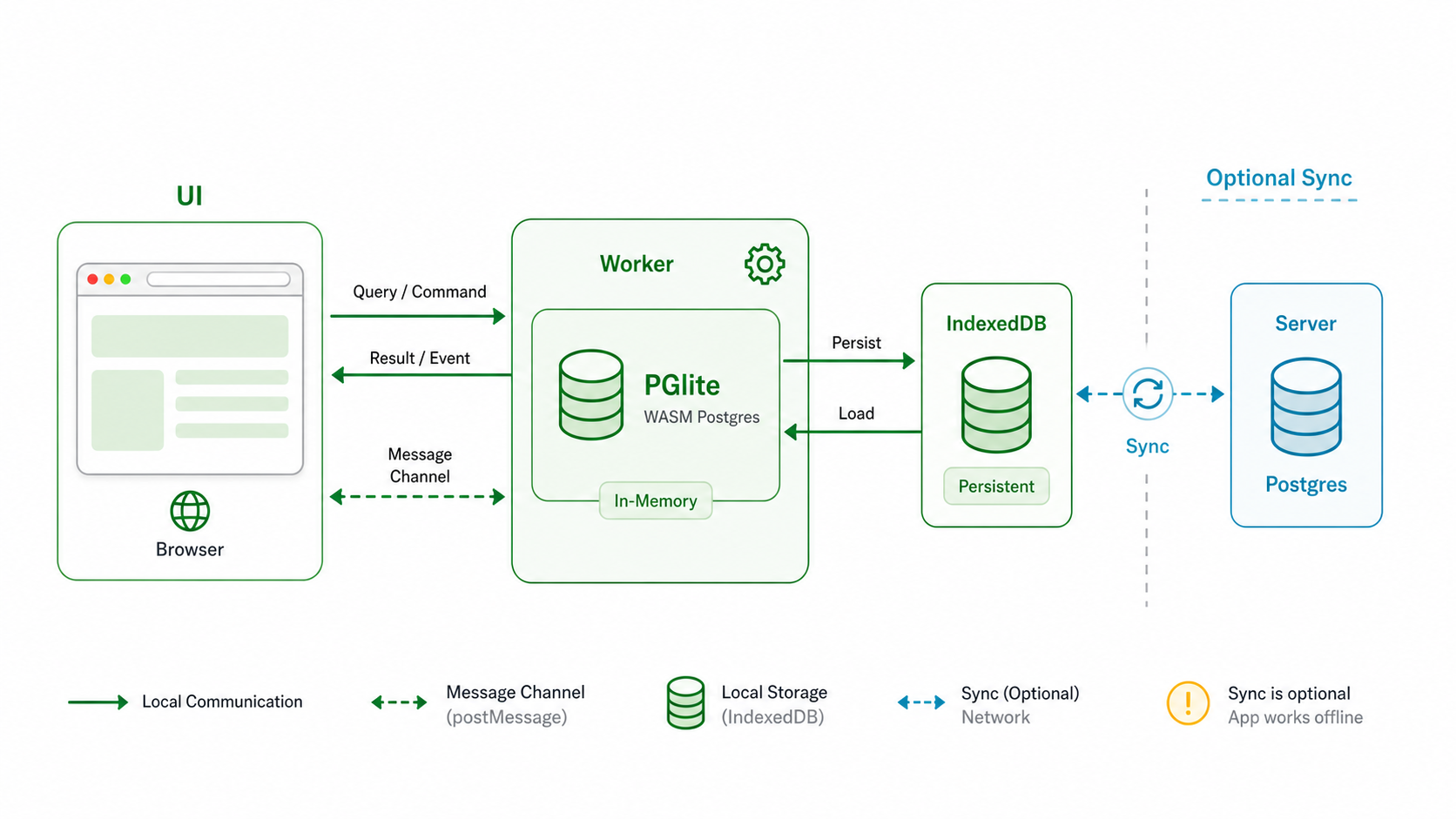
PGlite 本地优先架构示意图,UI 通过 Worker 访问 WASM Postgres,并持久化到 IndexedDB 来源:Codex image generation
适合先试的场景
第一类是离线表单、巡检清单、临时采集台这类轻量应用。用户先在本地录入和编辑,网络恢复后再提交。PGlite 支持在浏览器里用 idb://my-pgdata 把数据持久化到 IndexedDB,原型阶段可以直接用真实 SQL 描述约束、索引和迁移脚本,后续迁到服务端 Postgres 时心智负担较低。
第二类是可复现演示。很多 AI 工具或后台面板需要一组结构化样例数据,如果每次演示都要连测试库,权限和清理成本会拖慢节奏。把 PGlite 随页面加载,再写一段种子数据脚本,就能让产品、设计和开发拿到同一套初始状态。第三类是前端集成测试,尤其是需要复杂查询条件、分页和筛选的界面。比起手写一堆 mock 数组,用 SQL 准备状态更接近真实业务。
架构边界
我会把 PGlite 放进 Worker,让 UI 线程只发送查询命令和接收结果。官方 Multi-tab Worker 文档提醒,PGlite 只有单连接模型,浏览器多标签时可以用 PGliteWorker 代理多个标签,并通过 leader 机制让一个实例处理查询。这个边界一开始就划清,后面接入同步队列、重试或调试日志会轻很多。
持久化层优先选 IndexedDB。官方 Filesystems 文档也建议当前浏览器场景优先使用 IndexedDB VFS,因为 OPFS 路线在 Safari 上仍有兼容限制。需要注意的是,IndexedDB VFS 会在查询后把变更文件刷回 IndexedDB,所以大批量写入、频繁索引重建和超大附件都不适合直接塞进去。我的做法是把二进制附件留给对象存储,只把元数据、草稿和同步状态放在本地库。
如果界面需要自动刷新,可以再看 live extension。官方文档给出了 live.query()、live.incrementalQuery() 和 live.changes() 三种入口,适合让列表在底层表变化时更新。这里仍要保守使用,先从少量结果集和明确依赖表开始,避免把所有状态变化都包装成实时订阅。
落地建议
先写一份最小 schema,把迁移脚本、种子数据和清库脚本放在同一个目录。然后把所有写操作封装成命令函数,每个命令都返回业务事件,例如 draft_saved、sync_queued、sync_failed。最后再加一个同步出口表,字段包含本地变更编号、目标资源、幂等键、重试次数和最后错误。这样即使未来换成远端 Postgres 或 Electric 同步,也能保留清晰的本地状态边界。
PGlite 很适合把“能不能这样做”快速变成可交互页面。真正上线时,还要继续评估数据库体积、浏览器存储限制、多用户权限、审计日志和服务端冲突合并。把这些边界写清楚,它就是一个很实用的本地优先原型工具。