
给 AI 表单助手加自动填充前,我会先把建议写成可审查 Patch

最近给一个配置型后台页接 AI 表单助手时,我没有让模型直接返回整份表单。真实项目里的表单带着默认值、权限开关、依赖校验和草稿恢复。模型一次性吐出完整对象,看起来省事,实际会把用户刚改过的字段、隐藏字段和后端只读字段一起覆盖掉。后来我把模型输出改成可审查的 Patch,让它只描述准备改哪里、为什么改、改成什么。
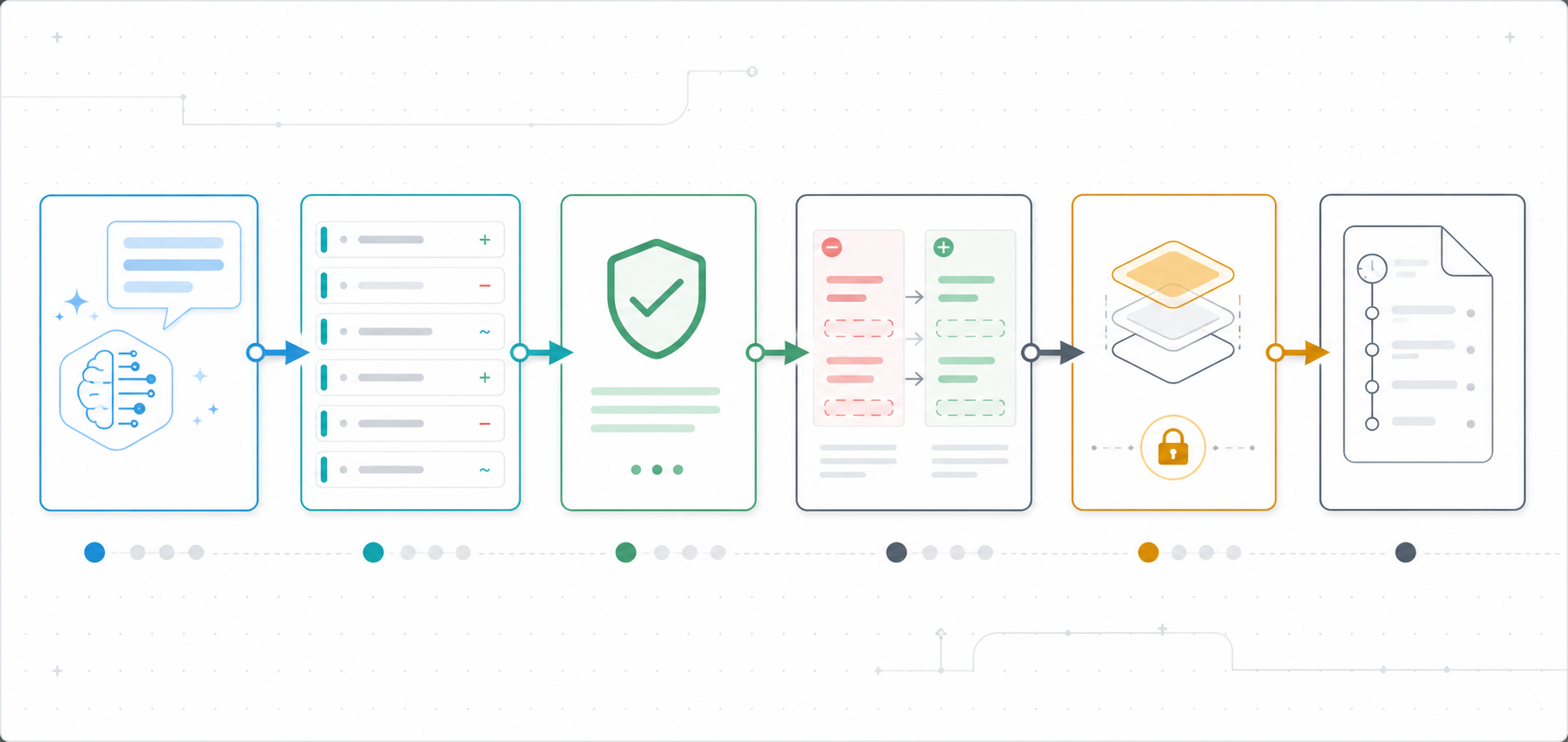
原创示意图:AI 建议先进入 Patch 协议,再经过校验、预览、人工确认和审计记录,最后写入表单状态。 来源:Codex image generation
问题背景
这个功能的目标是让用户粘贴需求说明后,AI 自动补齐任务名称、触发条件、通知模板和风险等级。RFC 6902 把 JSON Patch 定义为一组按顺序应用到 JSON 文档上的操作,常见操作包括 add、remove、replace、move、copy 和 test。这比整对象覆盖更适合表单助手,因为每一次建议都能落到明确路径上。
React 官方文档在对象状态更新里提醒,放进 state 的对象应当按只读方式处理,更新时创建新对象。Zod 的 .parse 可以校验输入并返回带类型的数据,.safeParse 可以用普通结果对象承接成功和失败。把这三件事放在一起,AI 建议就可以先成为待审查数据,再进入状态更新流程。
踩坑和关键难点
第一个坑是字段覆盖。早期版本让模型返回完整 FormValues,用户在等待 AI 时手动改了通知渠道,结果模型迟到后把旧渠道写回去了。第二个坑是路径漂移。表单结构一变,旧 prompt 里还在写 /notice/webhook,实际字段已经迁移到 /notifications/0/url,没有路径白名单时,错误会静默进入草稿。
第三个坑是无法解释。用户看到某个开关被打开,却不知道 AI 是根据哪句话做出的判断。开发侧也很难复盘,因为日志里只有最终对象,没有建议来源、验证失败原因和用户是否接受。
解决思路
我现在会把模型输出限制成一个很小的协议。每条建议必须包含 op、path、value、reason 和 sourceText。前端先用 Zod 校验这批建议,再检查路径是否在允许列表中,然后把 Patch 应用到当前表单快照的副本上,生成差异预览。用户点确认前,原始表单状态不变。
我还会限制操作集合。表单自动补全通常只开放 add、replace 和少量 test,暂时不开放 move 与 copy。表单字段带着普通 JSON 文档没有的约束,数组排序、受控组件和权限字段都可能让移动语义变复杂。越靠近用户数据,协议越要保守。
关键步骤
第一步是做字段路径表。把可被 AI 修改的字段列成 editablePaths,每个路径附带类型、展示名、是否需要二次确认和回滚文案。模型只知道这些路径,服务端或前端校验也只接受这些路径。
第二步是做双层验证。第一层验证 Patch 协议形状,比如 op 是否允许、path 是否存在、reason 是否为空。第二层验证应用 Patch 后的完整表单,让业务 schema 再跑一次。这样可以拦住类型正确但业务非法的建议,例如把重试次数改成 200。
第三步是做差异预览。预览里不要只显示最终值,还要显示当前值、建议值、理由和原始片段。对于自动执行、删除策略、外部 webhook 这类高风险字段,我会要求用户单独确认。低风险字段可以批量接受,但仍然写入审计日志。
第四步是处理并发。每批建议都带 baseRevision。如果用户在 AI 返回前继续编辑,前端会先比较当前 revision。命中同一路径时要求用户重新确认,这样迟到建议不会直接覆盖新输入。
可复用经验
AI 表单助手的价值不在于让模型一次填得多完整,重点是让每一次修改都可解释、可预览、可拒绝和可回滚。Patch 协议把生成结果从最终状态拆成修改意图,schema 校验把意图关进业务边界,差异预览把控制权交回用户。
这套做法也适合 Agent 配置页、自动化规则编辑器和 RAG 导入向导。只要页面存在复杂表单,我都会先问四个问题:哪些路径允许 AI 改、哪些字段需要二次确认、Patch 失败时如何展示、审计日志能否还原当时的建议。答案写清楚以后,AI 自动补全才像一个可靠的协作者,也能避免它变成突然改状态的黑盒。
主要来源
RFC 6902: JavaScript Object Notation JSON Patch