
给 Electron 长任务补取消按钮时,我会先把 AbortSignal 传到底

最近给一个 Electron AI 工具补“取消任务”时,我发现最容易被低估的地方并非按钮本身。按钮点下去很简单,难的是让本地索引、批量文件读取、向量化请求、子进程和临时文件清理都知道这次运行已经结束。否则 UI 显示已取消,后台仍在跑,下一次任务还可能复用到半截状态。
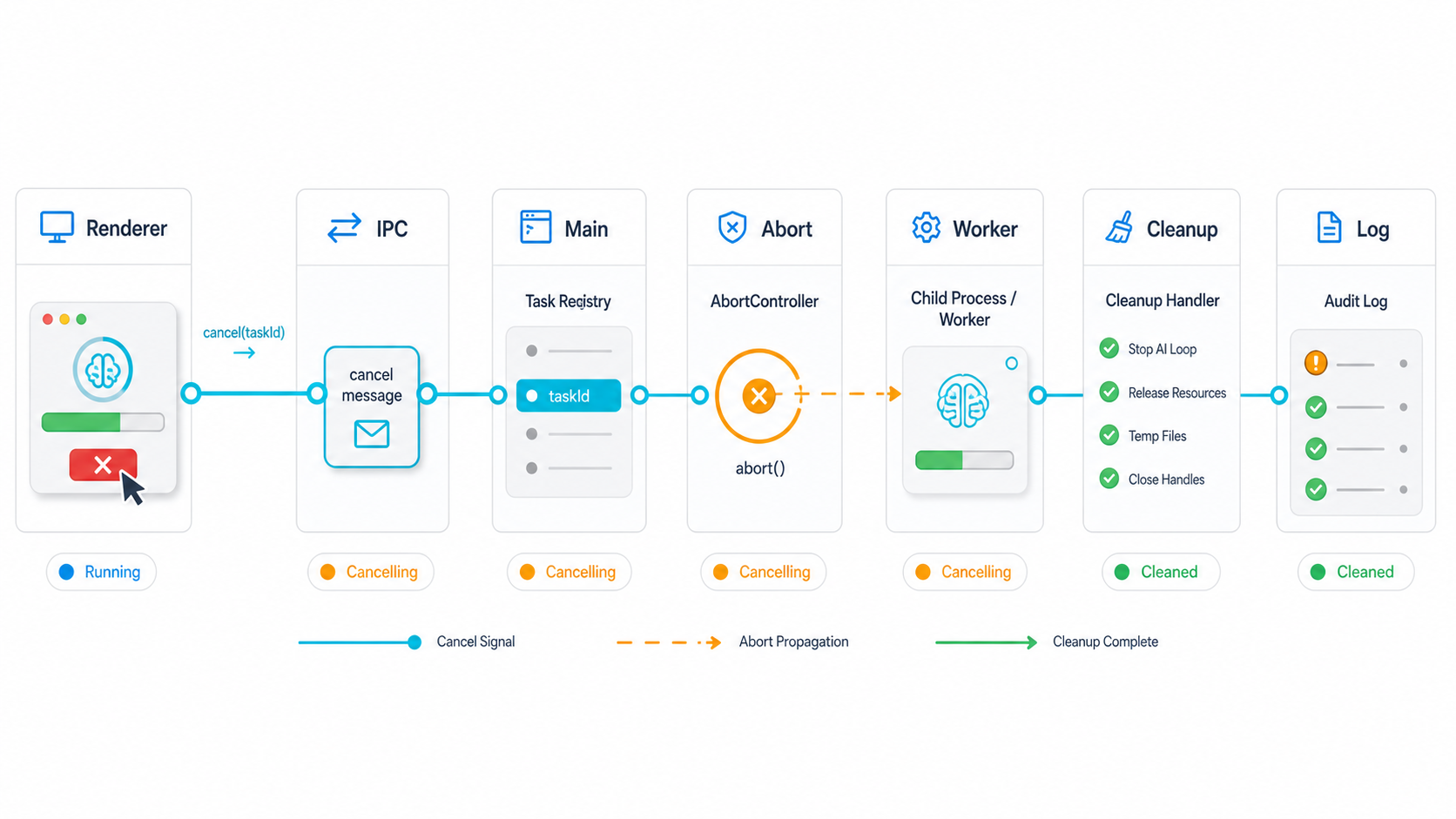
原创示意图:取消动作从渲染进程进入主进程任务注册表,再传递到执行层、清理器和审计日志。 来源:Codex image generation
问题背景
Electron 的渲染进程适合承接用户交互,主进程更适合收口本地能力。官方 ipcMain 文档说明,它用于处理来自渲染进程的异步和同步消息。MDN 的 AbortController 文档则给了一个清晰模型:创建 controller,通过 signal 传给异步操作,需要停止时调用 abort()。Node.js child_process 文档也支持在相关 API 里传入 AbortSignal。这些能力放在一起,取消链路就不应停在 React 状态里,而要成为一条从 UI 到执行层的协议。
踩坑和关键难点
第一个坑是只改前端状态。早期我在任务面板里把按钮从运行中切到已取消,用户确实得到了反馈,但主进程的批处理循环还在继续写缓存。结果下次打开知识库时,进度条从一个奇怪的文件序号开始,排查才发现取消事件没有进入任务执行器。
第二个坑是没有统一的任务注册表。桌面端任务经常跨好几层:渲染进程发起导入,主进程创建任务,Worker 做切片或解析,外部命令处理文件。若每一层只保存自己的局部状态,取消时就不知道该停谁、该等谁、哪些资源需要释放。
第三个坑是把取消当异常吞掉。取消确实会中断流程,但它不是失败。日志里如果只剩一个通用 error,用户看不出是主动取消还是任务崩溃,开发侧也无法统计哪些步骤经常被取消。
解决思路
我现在会让主进程维护一个 task registry。每个任务创建时生成 taskId、runId、AbortController、状态机和清理函数数组。渲染进程只能通过 preload 暴露的受控方法发送 task.cancel(taskId),主进程收到后先确认任务存在,再调用对应 controller 的 abort(),随后把状态从 running 改成 cancelling。
执行层只认 AbortSignal。无论是本地循环、Fetch 请求、Node 子进程,还是 Electron utilityProcess 包起来的重活,都要接收同一条 signal。能原生支持 signal 的 API 直接传入;不能支持的旧函数,就在循环边界检查 signal.aborted,并提供显式 cleanup。这样取消动作不会只停在某一个模块。
关键步骤
第一步是定义取消协议。UI 发送 taskId 和用户动作来源,不发送进程句柄、路径或命令参数。主进程根据 registry 查找任务,避免渲染层拿到过强能力。
第二步是在每个长任务入口创建 controller,并把 signal 继续传给下游函数。代码审查时我会看一个很简单的点:凡是可能超过一两秒的函数,都要么接收 signal,要么说明它为什么不需要取消。
第三步是收口清理动作。临时目录、文件句柄、数据库事务、子进程和内存缓存都注册到 cleanup 队列。取消发生后先停止新增工作,再等待当前可中断点退出,最后按反序执行清理。这里不要依赖 UI 页面是否还活着,清理必须在主进程侧完成。
第四步是把结果写成可区分事件。我的日志会记录 task.cancel.requested、task.abort.sent、task.cleanup.done 和最终状态。用户主动取消写成 cancelled,异常退出写成 failed,超时写成 timeout。状态分清以后,重试按钮、提示文案和排障统计都会简单很多。
可复用经验
取消按钮的价值在于缩短一次错误选择的成本。对 AI 桌面端来说,用户很可能中途发现选错目录、提示词写错,或本地资料太大。可靠取消链路能让他们快速回到可操作状态,也能减少后台残留任务对后续运行的污染。
我的默认做法是把取消当作一等协议:渲染进程只发意图,主进程持有 controller,执行层接受 signal,清理器负责资源释放,日志记录完整结果。只要这条链路打通,后面无论换 Worker、子进程,还是接入新的本地自动化工具,都能沿用同一套取消语义。