
给个人项目加后台任务时,我会先用 Cloudflare Queues 接住 Cron

很多个人项目都会把清理、同步、聚合和通知塞进用户请求里。访问量小时看不出问题,一旦第三方 API 变慢,页面响应也会跟着抖。我的默认做法是把入口拆成两段:Cron Triggers 只负责按 UTC 时间唤醒 Worker 并投递任务,Cloudflare Queues 负责缓冲、批量交付、重试和失败隔离。
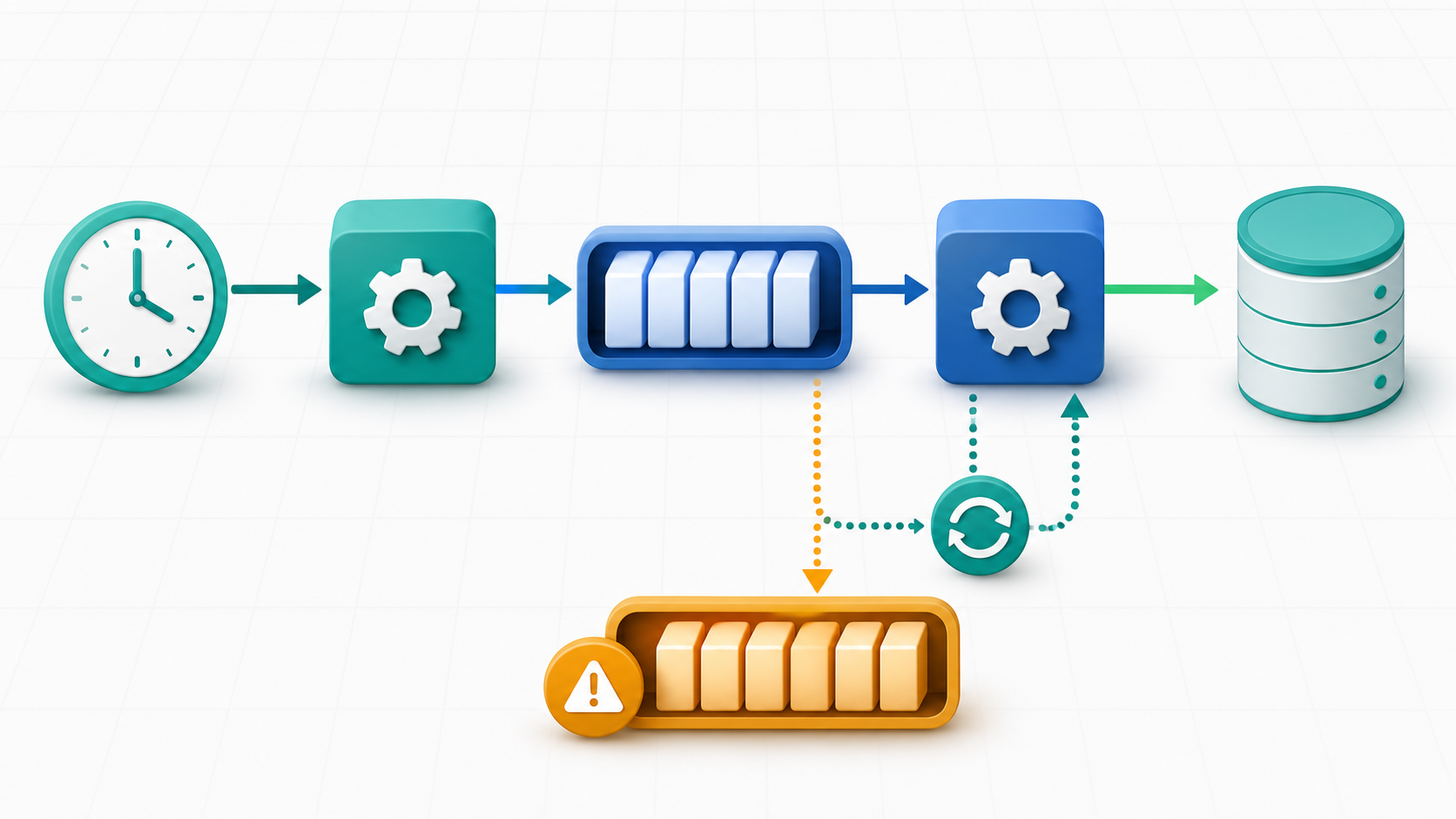
原创示意图:从定时触发、任务投递、队列缓冲、消费者处理到重试和死信队列的轻量后台任务流程。 来源:Codex image generation
定时入口只负责投递
Cloudflare 文档说明,Cron Triggers 会把 cron 表达式映射到 Worker 的 scheduled() handler,适合周期性维护、调用外部 API 收集数据这类任务。这里我会克制一点,scheduled() 里只生成结构化消息,例如任务类型、运行时间、幂等键和参数引用,然后写入队列。
await env.JOBS.send({
type: "sync-feeds",
runAt: Date.now(),
idempotencyKey: crypto.randomUUID()
});这样定时入口不会因为某条数据异常而卡住整批任务,真实处理逻辑也能放到 Queue consumer 里独立观察。后续要调大批量、加延迟、接死信队列,都不用改 cron 本身。
队列处理要可恢复
Queues 的 JavaScript API 把发送方称为 producer Worker,把接收方称为 consumer Worker;同一个 Worker 也可以同时承担两种角色。个人项目可以先用一个 Worker 降低部署复杂度。消息体要小而明确,官方 API 文档把单条消息大小限制放在 128 KB 以内,所以队列里只传引用和上下文,完整 HTML、大对象和二进制内容应放在 R2、D1 或外部存储。
消费端第一件事是做幂等。Cloudflare 的交付保证文档说明,Queues 默认提供至少一次投递,少数情况下同一消息可能被处理多次。凡是会写数据库、发邮件或调用外部接口的任务,都要带幂等键。插入记录时用唯一约束,调用外部 API 时把幂等键传给上游,日志里也记录它,排障会轻很多。
批量、重试和死信队列
Queues 默认按批次交给 consumer,官方文档给出的默认值是最多 10 条、最长等待 5 秒。先用默认值通常够用,等任务量变大后,再根据延迟和外部 API 写入成本调整 max_batch_size 与 max_batch_timeout。如果单条处理成功,就尽早 ack(),后面某条失败时,已确认的消息不会跟着整批重投。
失败消息要提前留出口。Dead Letter Queues 文档说明,消息达到 consumer 的重试上限后,如果配置了 DLQ,会被写入死信队列;没有配置时会被永久删除。我会在上线前就建一个 jobs-dlq,用于回放、修数据或补兼容逻辑。Cloudflare Pricing 页面当前显示,Queues 可在 Workers Free 计划使用,Free 计划包含每日 10,000 次标准操作,轻量维护任务可以先在这个额度内验证。
我会这样落地
第一版不用急着抽象成通用任务平台。先在 Wrangler 里配置一个 producer binding 和一个 consumer binding,cron 只绑定到投递逻辑;每条消息只存任务名、参数引用、运行时间和幂等键;consumer 里按任务类型分发到小函数,成功后 ack(),可恢复失败用 retry() 或延迟重试,不可恢复失败交给 DLQ。这样代码量很小,但已经有了缓冲、重试和回放窗口。
上线后我会重点看四个指标:每次 cron 是否按预期触发,队列积压是否持续增长,单条任务耗时是否接近上游 API 的限流阈值,DLQ 是否开始堆积。只要这四项可见,个人项目的后台任务就能从脚本式维护升级成可观察的生产流程。后续再接 R2 存输入文件、D1 记录任务状态或 Workers Logs 做查询,都会自然很多。
主要来源
Cloudflare Queues JavaScript APIs
Cloudflare Workers Cron Triggers
Cloudflare Queues Batching, Retries and Delays