
我给 RAG + Agent 工作流补了一条可回放 Trace,排障速度快了很多

最近在做一个带知识库检索的 Agent 工作流时,我最难受的一件事不是模型答错,而是答错以后很难快速还原现场。同一个问题可能跨过前端请求、查询改写、向量检索、重排、工具调用和最终回答六七个环节,任何一段少了上下文,排查就会变成反复看日志、重放输入、再猜一次当时发生了什么。
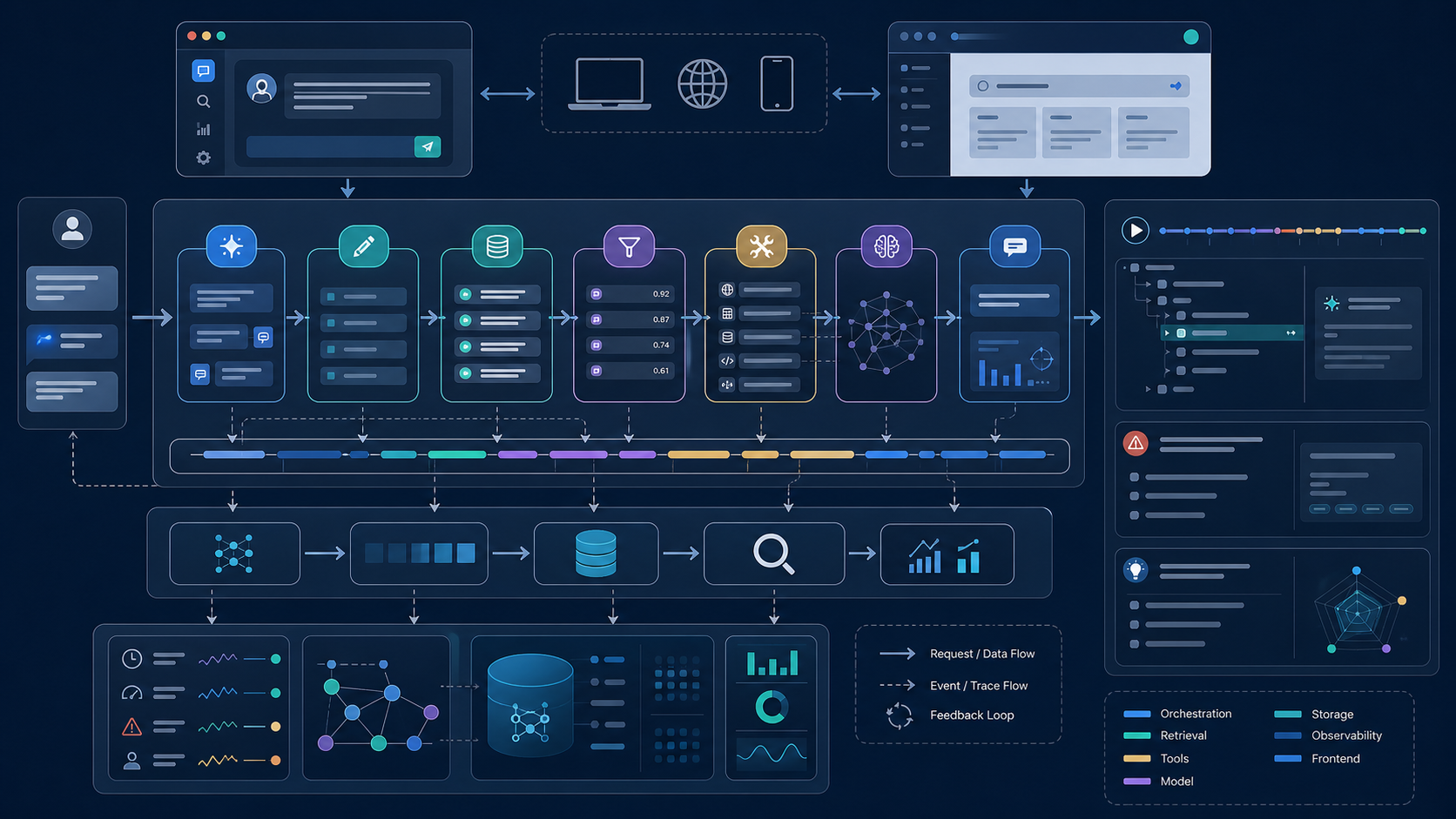
原创示意图:把查询改写、检索、工具调用、模型输出和前端问题面板收拢到同一条可回放 trace。 来源:Codex image generation
问题背景
这个链路一开始看起来并不复杂。前端把用户问题发给编排层,编排层决定是否需要改写查询,再去跑检索、重排和工具调用,最后交给模型组织回答。真正上线后问题开始集中出现:有时答案引用了旧知识块,有时工具已经成功执行但前端还显示失败,有时一次重试会把两轮检索结果混在一起。单看某一个服务的日志都能解释一部分现象,但很难回答“这次用户实际经历了什么”。
OpenTelemetry 对 trace 的定义给了我一个很实用的视角:把一次请求看成一条 trace,再把查询改写、检索、重排、工具调用这些动作拆成 span。OpenAI Agents SDK 也内置了 tracing 概念,说明 Agent 任务天然适合被当成多步骤执行流来观察。等我把这两个思路放到同一个项目里之后,调试方式才真正稳定下来。
我踩到的几个坑
第一个坑是 trace id 只存在后端。前端只拿到了最终回答和一个模糊错误提示,用户报问题时我们只能按时间猜是哪次请求。第二个坑是检索阶段记录得太粗,只知道命中了哪些 chunk,不知道命中前的查询改写版本、召回数量、重排分数和被过滤掉的原因。第三个坑是工具调用和模型回答分开存放,导致一次“回答异常”往往要同时翻三处日志。第四个坑是重试没有继承上下文,新的执行把旧的状态覆盖掉,回放时看到的是修复后的现场,丢掉了第一次失败的关键线索。
解决思路
我后来把整条链路改成“请求先拿 trace,再允许执行”。具体做法很简单:请求进入编排层的第一刻先生成 trace_id 和 session_id,前端、API 网关、检索层、工具层、模型层都带着这两个字段往后传。每个关键阶段都落一份结构化事件,最少包含输入摘要、输出摘要、耗时、命中数量、失败原因和上游 span_id。这样一来,任何异常都能从一个 trace 视角顺着看下去。
对 RAG 部分,我额外记录四类信息:原始问题、改写后的检索 query、召回候选列表摘要、最终注入上下文的 chunk 列表。这样做的价值很直接。以前看到“答案不准”只能猜是 embedding、切片还是 prompt 的问题,现在回放一条 trace 就能看出到底是没召回、召回过宽、重排失效,还是工具结果覆盖了知识库证据。
关键步骤
1. 在入口层统一生成 trace_id,并把它写回前端状态与服务端日志。 2. 把检索、重排、工具调用、模型生成都拆成独立 span,保留父子关系和耗时。 3. 为每个 span 记录足够排障的结构化字段,尤其是 query 改写结果、命中文档摘要和工具输入输出摘要。 4. 重试时不覆盖旧执行,而是在同一条 trace 下挂新 span,保证第一次失败现场仍可回放。 5. 在前端任务面板里加一个轻量 replay 视图,只展示业务同学真正关心的阶段状态和证据摘要。
可复用经验
这次改造后我对 Agent 与 RAG 联调有了一个更稳的判断:只要工作流里同时存在检索、工具调用和人工反馈,就应该尽早把它当成可观测系统来设计。日志当然还要保留,但只靠分散日志很难支撑稳定排障。把 trace 视角先立住,再决定哪些字段该采样、哪些内容只存摘要、哪些步骤要支持回放,后面的前端问题面板、失败归因、告警聚合都会轻很多。
我现在会优先做三件事:第一,把每次用户请求绑定唯一 trace;第二,把检索证据链完整保留下来;第三,把重试设计成可比较的多次执行,而不是覆盖现场。这样即使模型输出仍有波动,工程团队也能更快判断问题落在哪一层,修复效率会稳定很多。