
接 AI 流式输出时,我会先把前端事件契约写成可回放协议
最近给一个 AI 工作台补流式输出时,我又遇到熟悉的问题:后端很快开始吐字,前端也能逐字渲染,可一旦加入工具调用、引用来源、错误恢复和重新连接,原本简单的“流式文本”就变成了状态同步问题。我的做法是先暂停 UI 细节,把前端真正需要消费的事件契约写清楚,再让渲染层只做一件事:按顺序把事件折叠成当前界面状态。
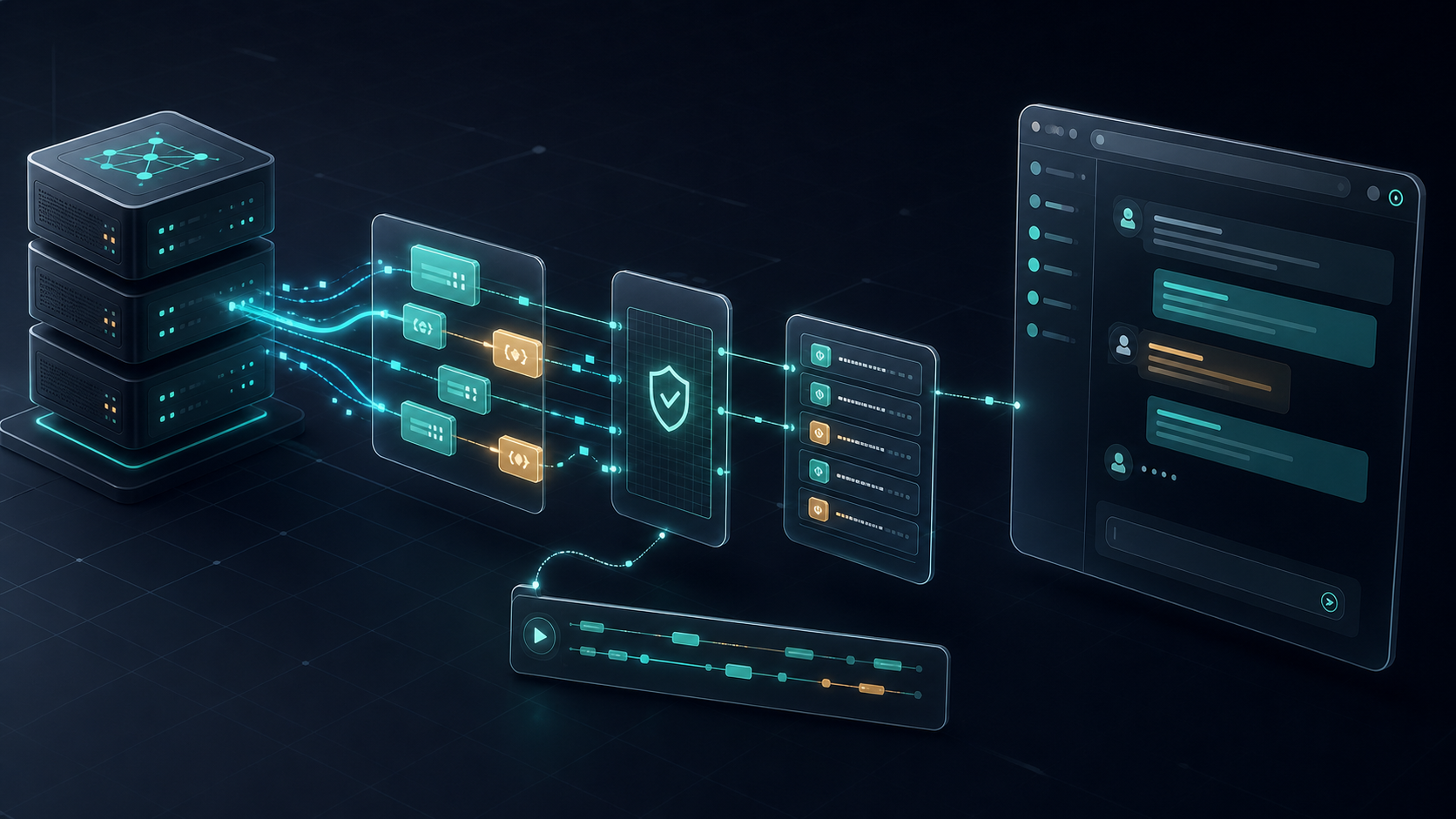
原创示意图:把模型输出、事件整理、Schema 校验、回放缓存和前端渲染拆成可观察链路。 来源:Codex image generation
问题背景
浏览器侧承接流式数据通常会碰到两类接口。MDN 的 Server Sent Events 文档说明,EventSource 可以接收服务端持续推送的消息,事件流使用 text/event-stream,并通过空行分隔消息;MDN 的 ReadableStream 文档也说明,Fetch 的 Response.body 会给出可读流,前端可以逐块读取网络数据。Vercel AI SDK 的 Stream Protocols 文档进一步把文本流和数据流分开,数据流会用 SSE 格式承载更丰富的事件,例如文本片段、来源、工具调用和错误。
在真实项目里,直接把每个 chunk 当作文本追加很快会失控。RAG 引用可能晚于正文到达,Agent 工具调用会经历 start、delta、result 几个阶段,模型中途失败时还要展示可解释的错误,用户刷新页面后最好能恢复到同一个回答的最后状态。只靠一个 content += chunk,这些状态全都会挤在组件里。
踩坑和关键难点
第一个坑是事件粒度太粗。早期我只区分 message 和 done,结果工具调用开始后,前端只能猜哪一段是普通文本,哪一段是工具参数,引用卡片也只能等整段回答结束后补上。用户看到的是文字先出现,卡片随后跳动,调试时很难复现当时的顺序。
第二个坑是缺少确认点。流式请求天然会遇到断线、重试和重复投递。SSE 有 id 和重连语义,实际落地时我仍然会在业务层加入 runId、messageId、partId 和递增 seq。前端收到事件后先判断是否已经处理过,再进入 reducer,这样重复事件只会命中已确认状态。
第三个坑是 schema 漂移。Zod 文档里提到 .safeParse() 会返回包含成功数据或错误对象的普通结果,这很适合放在流式边界。我的经验是不要让渲染组件直接相信后端事件,所有事件都先经过 schema 校验,未知字段可以保留在 debug 面板里,未知类型则进入兼容分支,避免一次后端改动把整条消息渲染打断。
解决思路
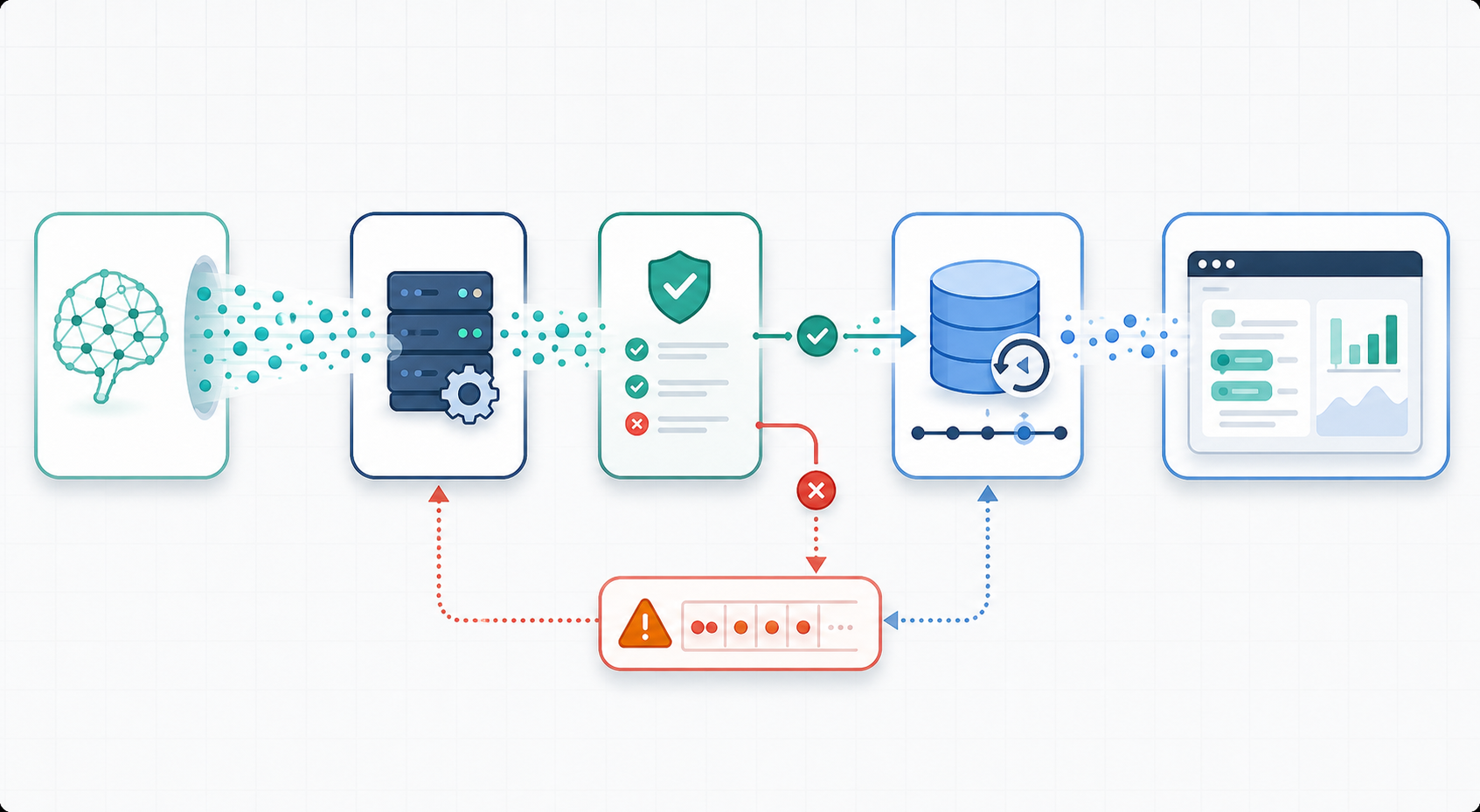
我把协议拆成一个 TypeScript 联合类型,大致包含 text.start、text.delta、text.end、tool.start、tool.delta、tool.result、source.add、error 和 done。每个事件都有 runId、messageId、seq、createdAt,和一个可选的 trace 字段。服务端负责把模型原始输出、工具执行回调和检索来源统一整理成这些事件,前端只消费整理后的协议。
前端状态采用事件折叠模型。收到事件后,先校验,再去重,再写入本地 replay buffer,最后交给 reducer 生成 UI 状态。聊天窗口不直接订阅网络流,它订阅的是折叠后的 message view model。这样网络层、协议层和 UI 层被分开,任何一层出问题都能用同一份事件日志重放。
关键步骤
第一步是在服务端加 normalizer。模型 token、工具事件、引用来源和错误都进入同一个出口,统一补齐 seq 和标识字段。这里不要把 UI 文案写死在服务端,只传结构化状态,例如 toolName、status、durationMs、sourceId。
第二步是在前端建 schema guard。每条事件进入 UI 前先 safeParse,成功后进入 reducer,失败后写入 stream_invalid_event 日志。这个日志要带 seq、事件类型和错误路径,排查时比截图有用很多。
第三步是做 replay buffer。我通常只保留最近一次 run 的事件数组和最后确认的 seq。刷新页面后,先用本地 buffer 还原界面,再向服务端询问是否有后续事件。这样用户不会在刷新后看到一段空白回答。
第四步是给 UI 设置提交边界。正文可以逐字更新,引用卡片等到 source.add 后再挂载,工具结果等到 tool.result 后再展开。状态边界清楚后,界面抖动会少很多。
可复用经验
AI 流式输出的难点经常出在协议设计。文本只是其中一种事件,工具、来源、错误和完成信号都要拥有同等级的事件身份。只要事件可校验、可去重、可回放,后续无论换成 SSE、Fetch Stream,或接入某个 SDK 的数据流协议,前端都能稳定承接。
我现在会把“能否重放”当作流式功能的验收条件:拿一份事件日志,离线跑一遍 reducer,界面状态应该和线上一致。这个标准很朴素,却能逼着我们把事件边界、错误路径和 UI 提交点想清楚。