
Electron 桌面端的 RAG 热更新,我为什么把监听、切片和索引任务都收回主进程

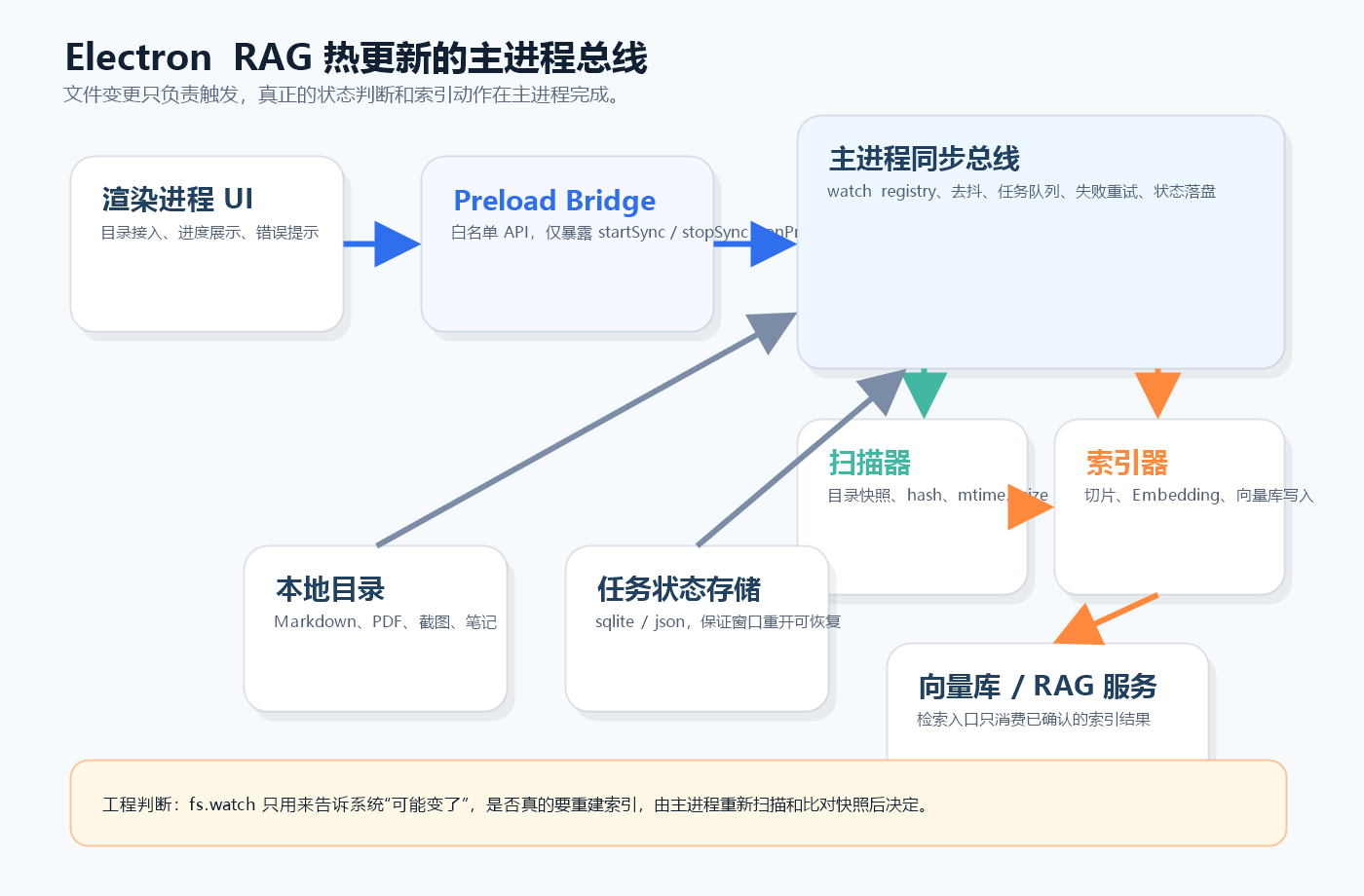
原创示意图:文件变更只负责触发,状态判断和索引动作统一在主进程完成。 来源:Coriander 原创
最近在做一个桌面端知识库工具,用户会把本地 Markdown、PDF 和截图目录直接接进来,希望内容一落盘就能进入索引,再被 Agent 检索到。第一版为了省事,把文件监听、切片调度和索引触发都放在渲染进程里,界面逻辑和业务逻辑混在一起,最开始看起来很快,跑一阵子问题就全出来了。
问题背景
这个场景和普通 Web 应用差别很大。桌面端既要碰文件系统,又要处理长任务,还要承受窗口刷新、热更新、目录切换这些高频动作。Electron 官方对进程模型的定义很明确,主进程负责应用生命周期和原生能力,渲染进程负责页面展示;IPC 教程也强调,很多原生任务只能通过进程间通信完成。等我把索引链路跑起来以后,才真正体会到这条边界为什么重要。
踩坑和关键难点
第一个坑是卡顿。目录稍微大一点,渲染进程就会同时处理监听事件、计算文件指纹、更新列表和展示进度,输入框明显掉帧。第二个坑是重复索引。窗口重开、页面热刷新、目录重新挂载,都会让监听器和任务队列重复注册,向量库里很容易出现重复 chunk。第三个坑是安全边界。Electron 的 context isolation 文档提到,预加载层应该只暴露白名单 API,不能把过宽的 IPC 能力直接丢给页面。我当时图快,桥接层太厚,后面排查问题非常费劲。第四个坑来自文件监听本身。Node 官方文档明确提醒,fs.watch() 在不同平台上一致性有限,所以它适合做变更信号,不适合直接充当最终数据依据。
解决思路
第二版我把思路改成“主进程同步总线”。渲染进程只负责三件事:发起同步、接收进度、展示结果。preload 只暴露 startSync、stopSync、onProgress 这种窄接口。主进程内部维护 watch registry、目录快照、任务队列和失败重试,把有状态的东西全都收拢到一个地方。文件系统事件到来以后,先做 800 毫秒去抖,再触发一次真实扫描;真正决定是否重建索引的条件,是 path + mtime + size + chunkHash 的比对结果,不是某一次 watcher 回调本身。
关键步骤
1. 先把渲染层改成命令式调用,只发请求,不直接碰文件系统。 2. 在 preload 做白名单桥接,每个 IPC 通道只对应一个明确动作,参数也做最小化。 3. 主进程维护目录级快照,把 fs.watch() 产出的事件合并后再进入扫描器。 4. 扫描器和索引器拆开,前者确认哪些文件真的变了,后者再负责切片、Embedding 和向量库写入。 5. 任务状态落到本地存储,这样窗口重开以后还可以恢复进度和失败原因。
可复用经验
这次复盘给我一个很稳定的判断:桌面端 AI 应用里,只要一段逻辑同时满足“依赖本地能力、运行时间长、需要持续状态”这三个条件,就应该优先放进主进程或独立 worker,而不是留在渲染层。UI 层越轻,问题越容易定位;任务状态越集中,自动化和 Agent 工具越容易复用。文件监听也一样,真正可靠的做法是把 watcher 当成提醒器,再用一次可复算的扫描流程收口。后来我把这个模式继续用到本地知识库同步、插件安装、批量导入和 Agent 工具调度上,整体稳定性都比第一版高很多。