
把代码库交给 AI 前,我会先用 Repomix 打包一份上下文

把一个代码问题丢给 AI 时,最常见的翻车点并不在模型能力,而在上下文缺口。只贴一个报错、一段函数或几张截图,模型很容易忽略目录结构、配置文件、类型定义和调用链。Repomix 的价值在于把仓库先整理成一个可审计的上下文包,再交给 ChatGPT、Claude、Gemini 等工具做分析。它是 MIT 许可的开源项目,官方定位就是把整个代码库打包成 AI 友好的单文件格式。
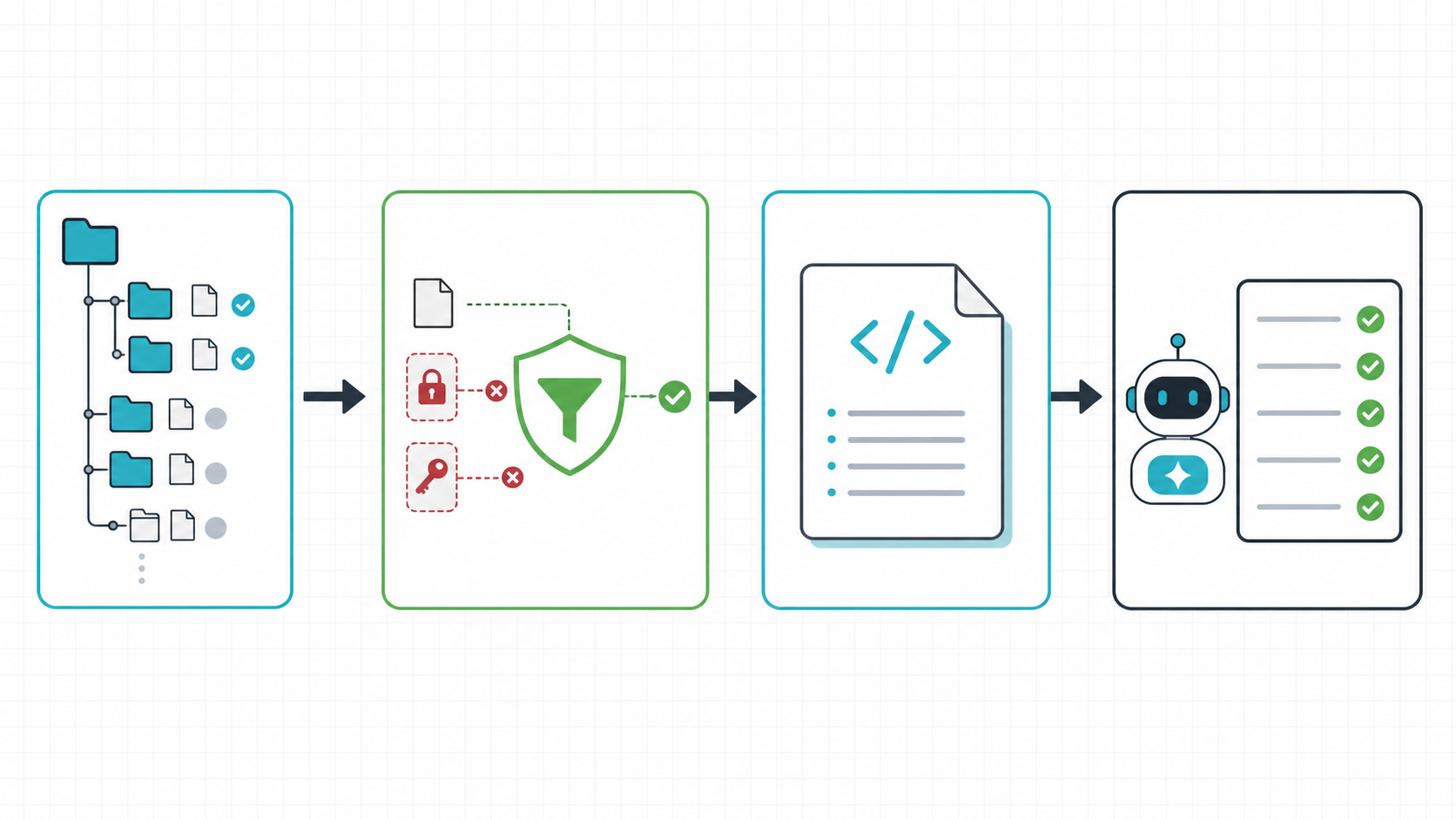
从选择目录、过滤敏感信息到生成 AI 上下文包的流程示意 来源:Codex image generation
适合什么场景
我更愿意把 Repomix 放在三类任务前面。第一类是重构规划,尤其是你要让 AI 先读完整模块边界,再给出拆分建议。第二类是代码审查,把相关目录、配置和测试一起打包,模型看到的证据会更完整。第三类是文档生成,先让 AI 理解真实目录和入口,再产出 README、迁移说明或架构备忘录。
它的官方快速开始很简单,在项目目录运行 npx repomix@latest,默认会生成 repomix-output.xml。如果团队想把输出给人读,可以用 repomix --style markdown。如果想进入后续脚本处理,可以改成 repomix --style json。这比手工复制几十个文件稳定得多,也方便把同一份上下文放进审查记录。
我会先做的三条边界
第一,先收窄范围。不要一上来打包整个单体仓库,可以从 src、docs、package.json、配置文件和相关测试开始。Repomix 支持 include 与 ignore 规则,用它们把日志、构建产物、临时文件和无关示例排除掉。
第二,保留安全检查。官方安全说明写明,Repomix 默认启用安全检查,并用 Secretlint 检测 API key、访问令牌、凭据、私钥和环境变量等敏感信息。即便如此,输出文件仍然应该人工快速扫一遍,特别是准备发给外部 AI 服务时。
第三,按任务选择压缩。Repomix 的 --compress 会用 tree-sitter 抽取函数签名、接口、类型和类结构,同时移除部分实现细节。它适合先看架构和 API 形状,未必适合排查具体业务 bug。我的做法是先用完整输出定位问题,如果上下文太大,再为架构审查生成一份压缩版本。
一个可落地的小流程
可以把 Repomix 当成 AI 协作前的打包工序。先写 .repomixignore,排除密钥、缓存、产物和大体积样例。然后用 repomix --style xml 生成默认上下文包,把输出文件和问题描述一起提交给 AI。最后把 AI 的结论和你实际采用的修改写回任务记录。这样做的好处是,每次对话都有同一份上下文基线,后续复盘时也能看清模型到底基于哪些文件给出建议。
如果团队已经在用代码助手,Repomix 不会替代 IDE 内的索引能力。它更像一个轻量的交接包,把仓库结构、关键文件和任务目标固定下来。对小团队来说,这个步骤能减少很多来回补文件的沟通成本,也能让 AI 输出从零散回答变成一次更像审查报告的分析。